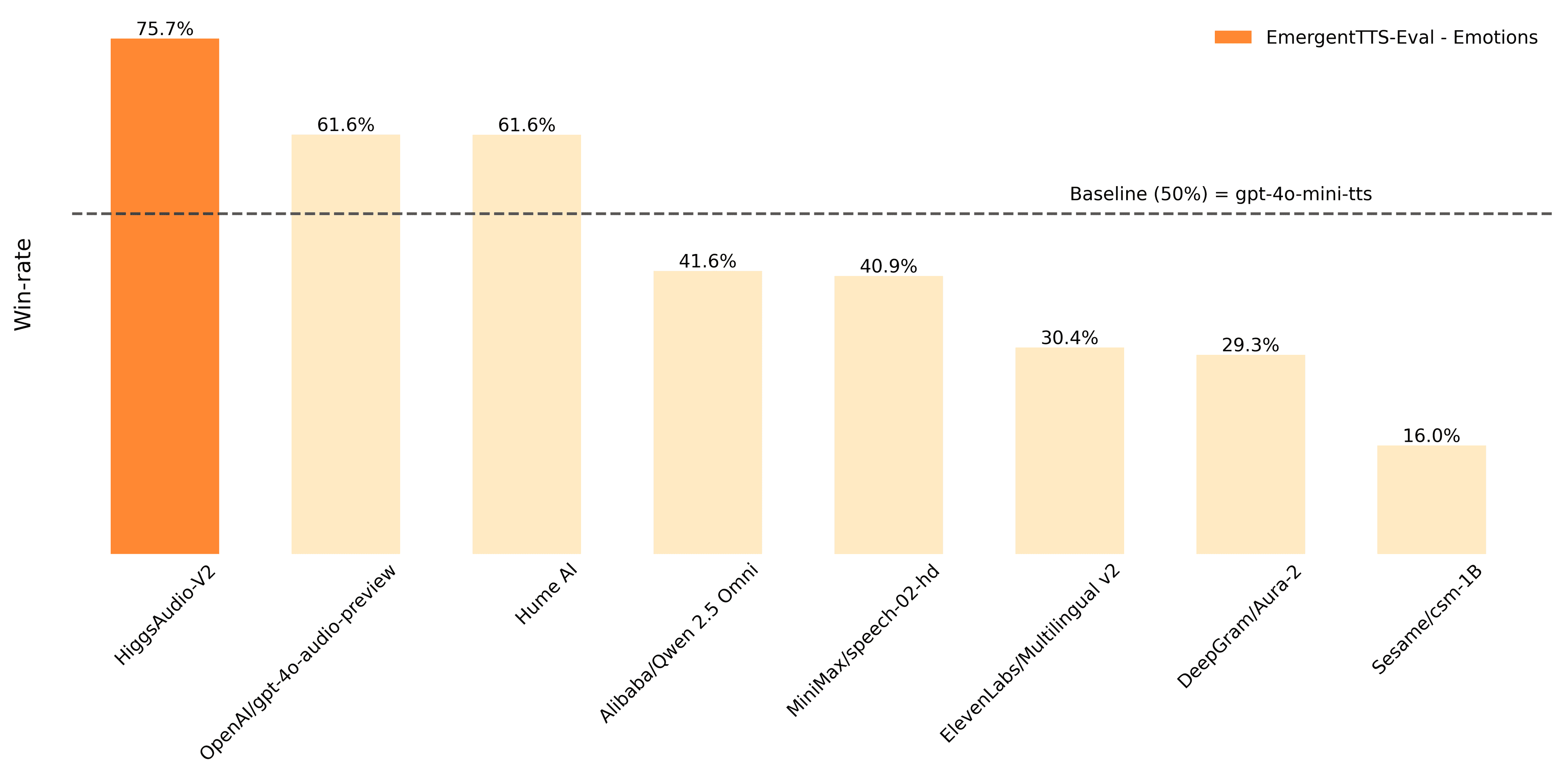Meituan/Text / LLM
Meituan Ships a Lighter, Sparser LongCat-Flash
The food-delivery giant's newest open model trims its mixture-of-experts design for more efficient inference under an MIT license.
Chronological
Every open-weight model release we've tracked, day by day — scroll the full chronology of open-source AI, from today's drops back through the year.
3 releases
The food-delivery giant's newest open model trims its mixture-of-experts design for more efficient inference under an MIT license.
The latest checkpoint in DeepSeek's V4 line leans into agentic workflows while keeping the permissive MIT license.
The MIT-licensed mixture-of-experts model returns in an updated build shipping with FP8 weights for cheaper inference.
1 release
The new mixture-of-experts model activates 37B parameters per token and targets English, Korean, and Spanish reasoning tasks.
3 releases
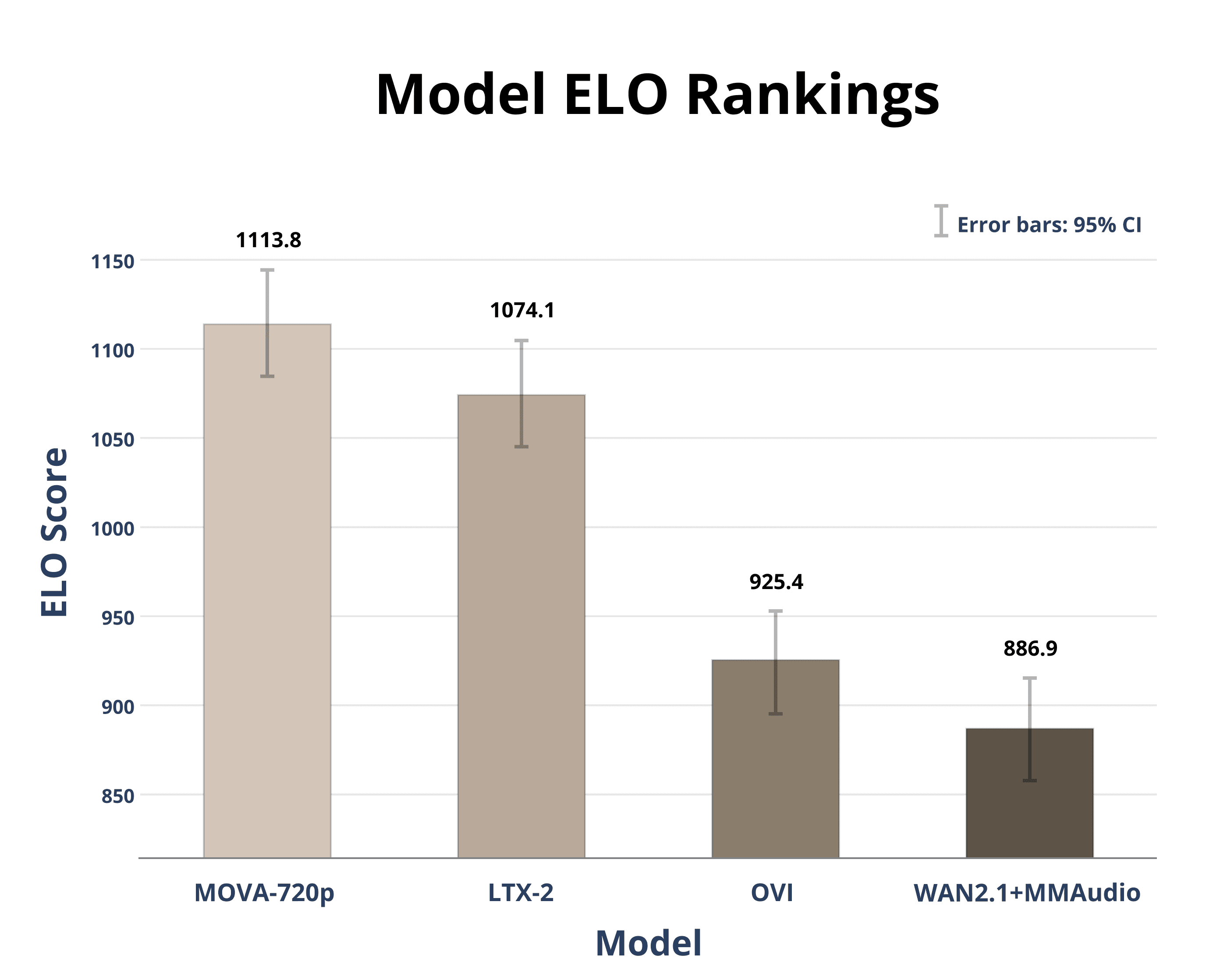
The company's new diffusion model handles text-to-video and image-to-video, with support for joint audio-video generation.
The Korean telecom carrier's latest open language model targets English, Korean, Chinese, Japanese, and Spanish under a permissive license.
The compact text-to-speech model promises voice cloning across languages from a footprint small enough to run without heavy hardware.
4 releases
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.
A 230M-parameter bidirectional encoder built for long-context English and German embeddings without a GPU.
The compact LFM2.5 encoder targets fast, long-context text embeddings without a GPU.
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.
1 release
A codec-native multimodal foundation model aims to understand live video and vision-language input in real time.
2 releases
Switzerland's open-model effort ships a 70-billion-parameter, multilingual and multimodal system that anyone can use, modify, and deploy.
A BitNet-quantized speech recognition model trades GPU dependence for efficient CPU inference in English and Chinese.
2 releases
A new open mixture-of-experts model with 16B total parameters and just 3B active is tuned to run on AMD's own accelerator stack.
Kuaishou's coding team ships an open mixture-of-experts model built on the Qwen3.5 MoE architecture and tuned for agentic development work.
1 release
The Korean AI firm's latest open release scales to 250 billion parameters with a mixture-of-experts design tuned for English and Korean.
1 release
A compact model handles both text-to-image generation and instruction-based edits at native resolution, under a permissive MIT license.
1 release
The Korean AI lab's preview release is a mixture-of-experts language model built for long-context, multilingual work.
1 release
A 27B-parameter vision-language model built to drive browsers and desktop apps like a human operator.
5 releases
A fully open multimodal model aims to reason jointly across audio, images, and long-form video.
A collaborative European effort ships a dense 30-billion-parameter model that claims top marks on both English and German benchmarks.
The 8-billion-parameter text embedding model claims the number one overall spot on the RTEB benchmark, with an eye toward agentic retrieval.
The Intern-S2 preview arrives as a very large multimodal system under a permissive Apache-2.0 license.
A new Apache-2.0 mixture-of-experts model that generates text through diffusion rather than left-to-right decoding.
2 releases
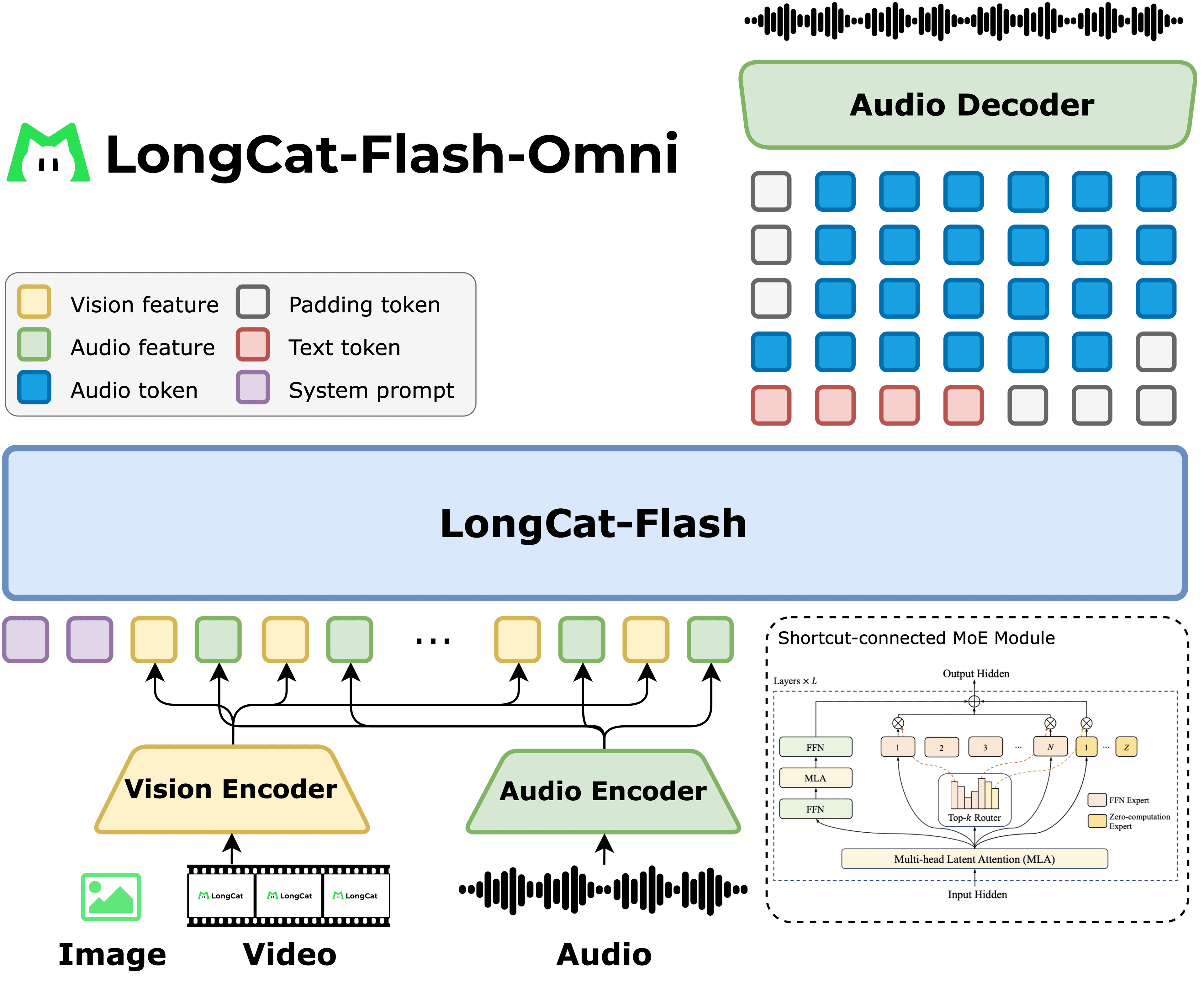
The lab's inaugural open-weights release is a mixture-of-experts system that takes image and audio inputs, shipped under a permissive Apache 2.0 license.
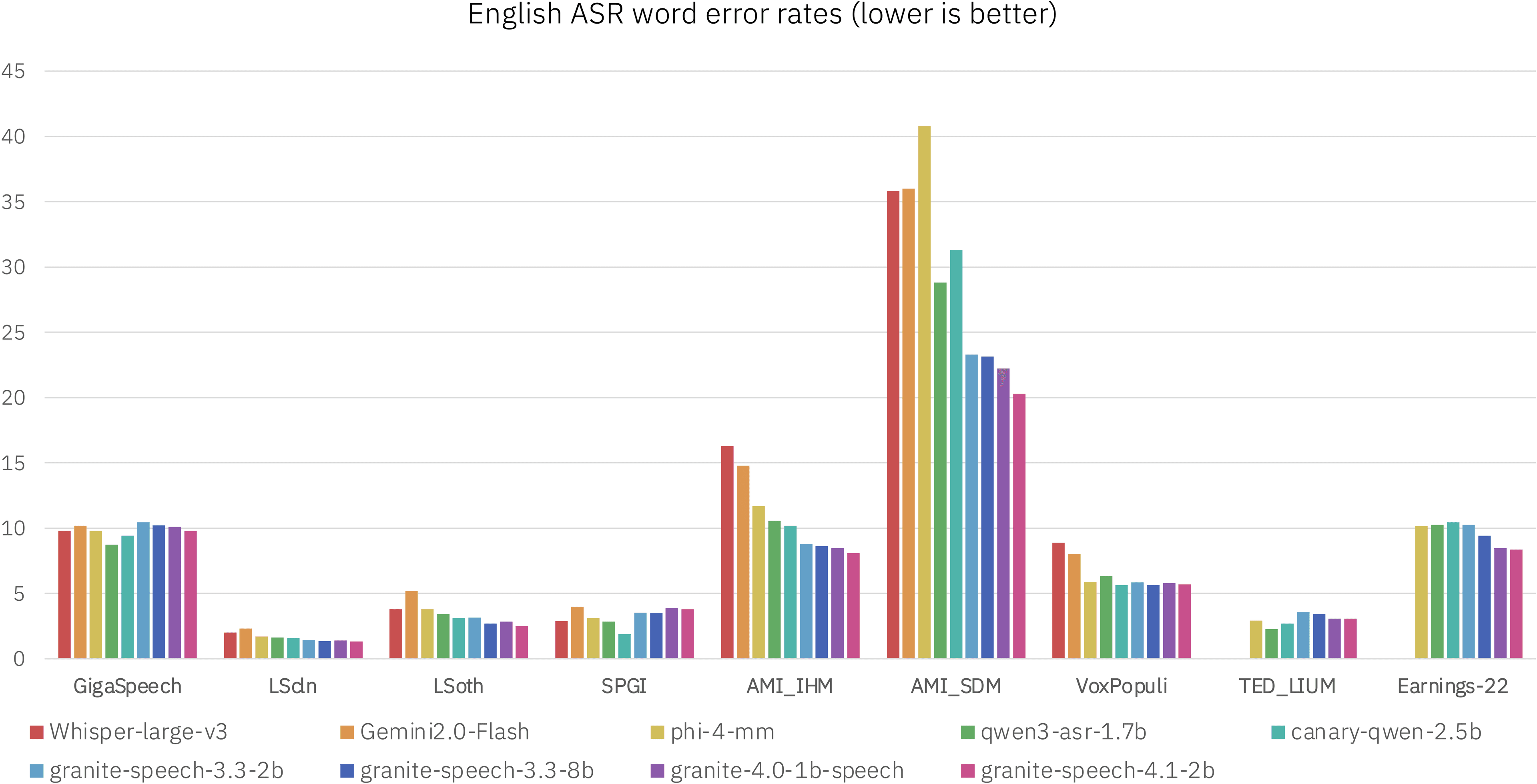
A Whisper-based ASR model that keeps every filler word and stamps timestamps to the individual word, now covering English and German.
3 releases
A compact 1B-parameter text embedding model claims the top overall spot on a retrieval benchmark aimed at reflecting real-world use.
The Chinese research group's new vision-language model targets streaming understanding of video and images rather than static frames.
An MIT-licensed speech recognition model targeting Russian, English, and Kazakh arrives on Hugging Face.
4 releases
A new mixture-of-experts model learns to reason through reinforcement learning alone, without human-annotated chains of thought.
A new Apache-licensed model family folds bilingual text-to-image generation and instruction editing into one system.
The AI coding startup puts a version of its Laguna family on Hugging Face under the permissive OpenMDW license.
A compact 0.8B vision-language model aims to parse full documents—text, tables, and formulas—in a single pass.
1 release
Alibaba's Qwen team debuts a text-to-song model that produces high-fidelity tracks complete with vocals.
1 release
Alibaba's Wan team releases an Apache-2.0 image-to-video model built for music-driven dance generation.
1 release
A DiT-based mixture-of-experts model activates just 3B parameters per step and ships under an Apache 2.0 license.
1 release
A new 30B mixture-of-experts model from NVIDIA handles both listening and speaking within a single audio-text architecture.
1 release
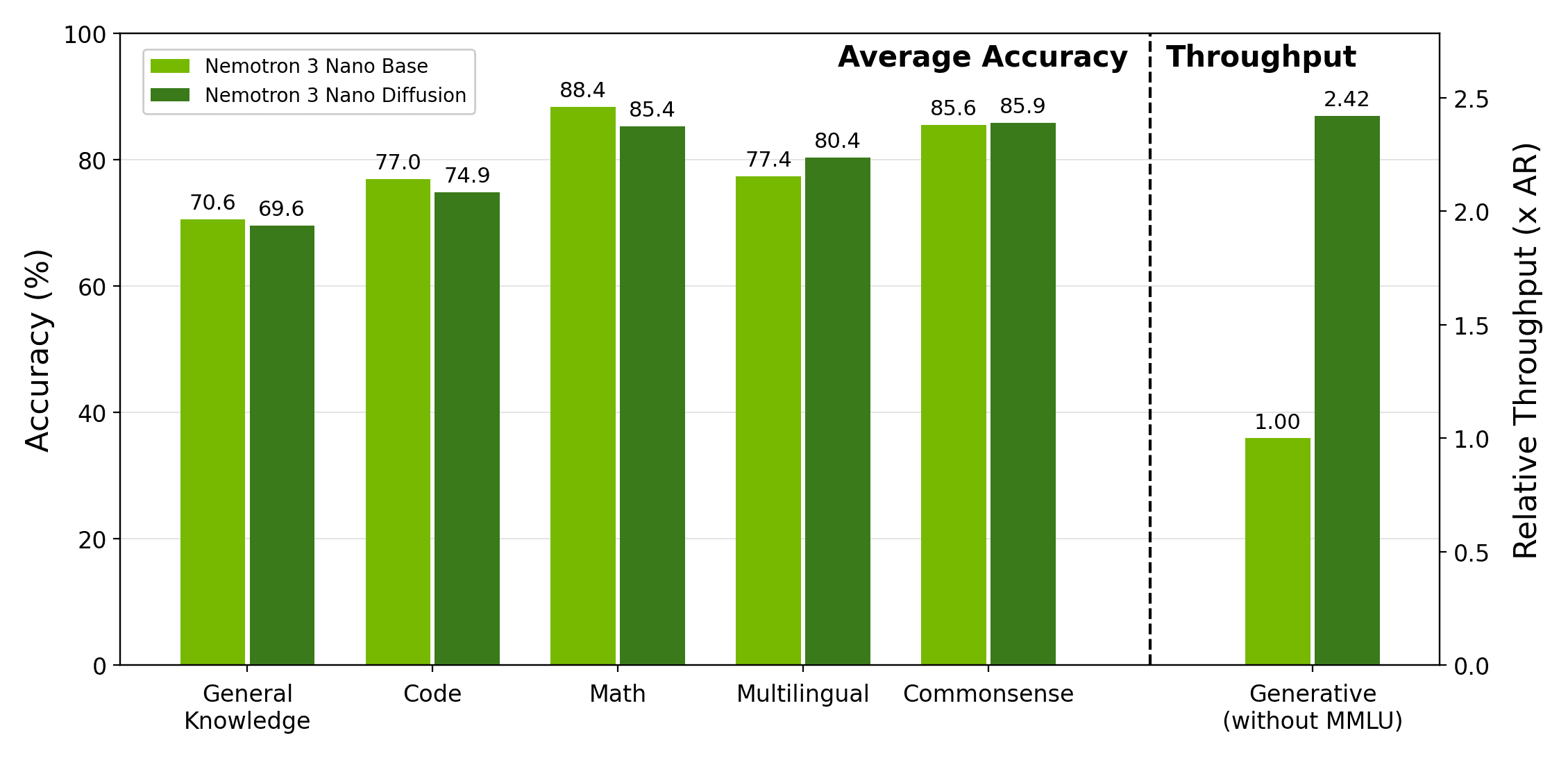
The multilingual instruct model activates 28B parameters per token and leans on hybrid attention for efficiency at scale.
1 release
A ternary-weight 27B model with hybrid attention aims to run large-model reasoning on everyday hardware.
1 release
The company's latest mixture-of-experts model arrives as an openly licensed conversational LLM on Hugging Face.
9 releases
A new edge-optimized variant of NVIDIA's Cosmos world-model line aims to run generative video where the compute lives.
A DMD2-distilled build of Qwen-Image trades sampling steps for speed while keeping the original model's output profile.
The new open-weights family adds a mixture-of-experts design, encoder-free multimodal inputs, and an optional thinking mode.
The new Apache-2.0 mixture-of-experts model activates just 6B parameters per token, trading raw density for cheaper inference.
A Mamba-2 mixture-of-experts model claims top marks in both English and German benchmarks.
A 230-million-parameter model built to run on constrained hardware like Raspberry Pi and edge robotics.
A 230-million-parameter language model built to run locally on constrained hardware like the Raspberry Pi.
A 230-million-parameter language model built to run on hardware as modest as a Raspberry Pi.
An open image-to-video world model aims to bridge physically grounded generation and robot policy learning.
3 releases
The 4-billion-parameter vision-language model targets on-screen and mobile automation, built atop Qwen3-VL.
A new open model tackles multi-instrument transcription of real audio mixes, converting songs directly into editable MIDI.
The Chinese delivery giant continues its push into open AI with a new text model on Hugging Face.
2 releases
A new foundation model brings zero-shot, in-context learning to classification and regression on structured tables.
A single 7B model from SenseTime folds vision-language understanding, image generation, editing, and perception into one system.
2 releases
The new flagship arrives as a mixture-of-experts system with FP8 weights and open reasoning capabilities under a permissive license.
A lighter, faster member of DeepSeek's V4 line arrives on Hugging Face under a permissive MIT license.
1 release
The new dense model ships in GGUF format under a permissive MIT license, aimed at local and self-hosted deployment.
3 releases
A 230-million-parameter multilingual model built to run efficiently at the edge rather than in the cloud.
A 75-billion-parameter mixture-of-experts reasoning model that activates just 9 billion parameters per token.
The 75B-parameter model activates just 9B per token and ships in NVIDIA's NVFP4 format for efficient inference.
1 release
The flagship of a new open model family arrives under a permissive MIT license, with reasoning among its stated strengths.
5 releases
A lightweight image-editing framework claims results rivaling 10B-scale models, and it's already running in the browser.
Alibaba's new MoE model acts as a language world model, generating the environments that agents act within.
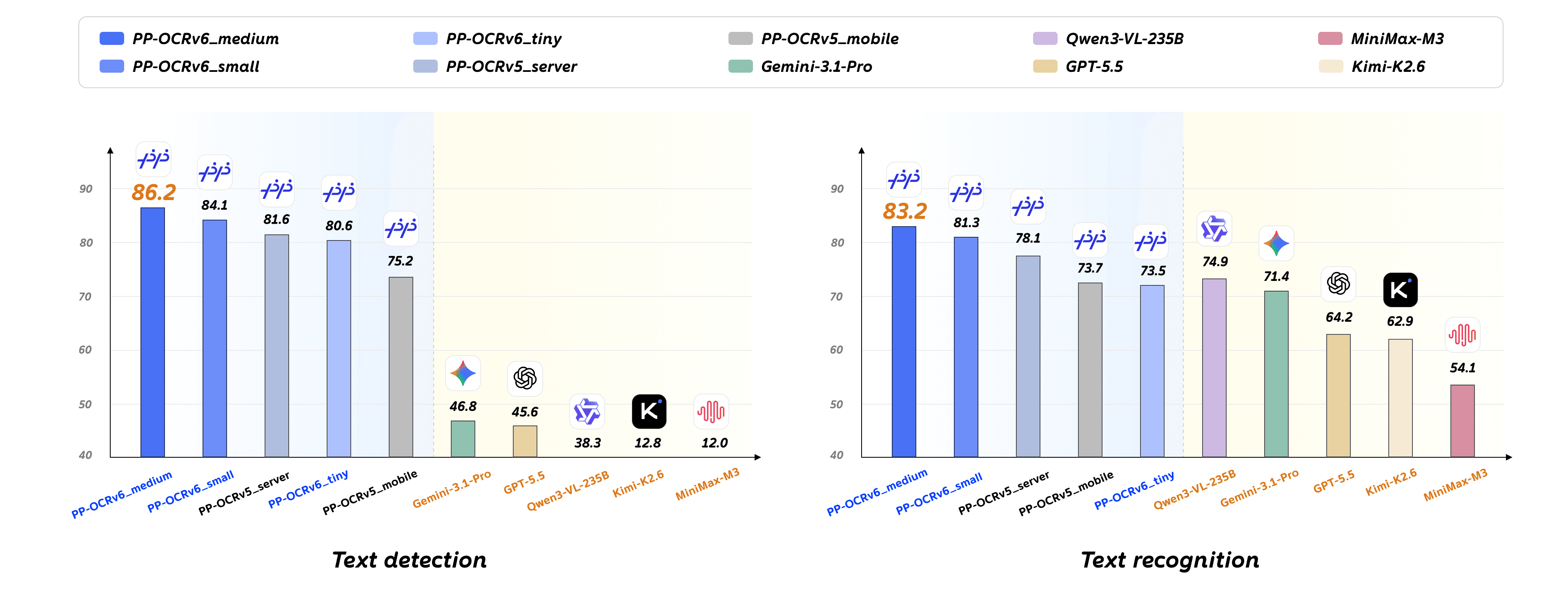
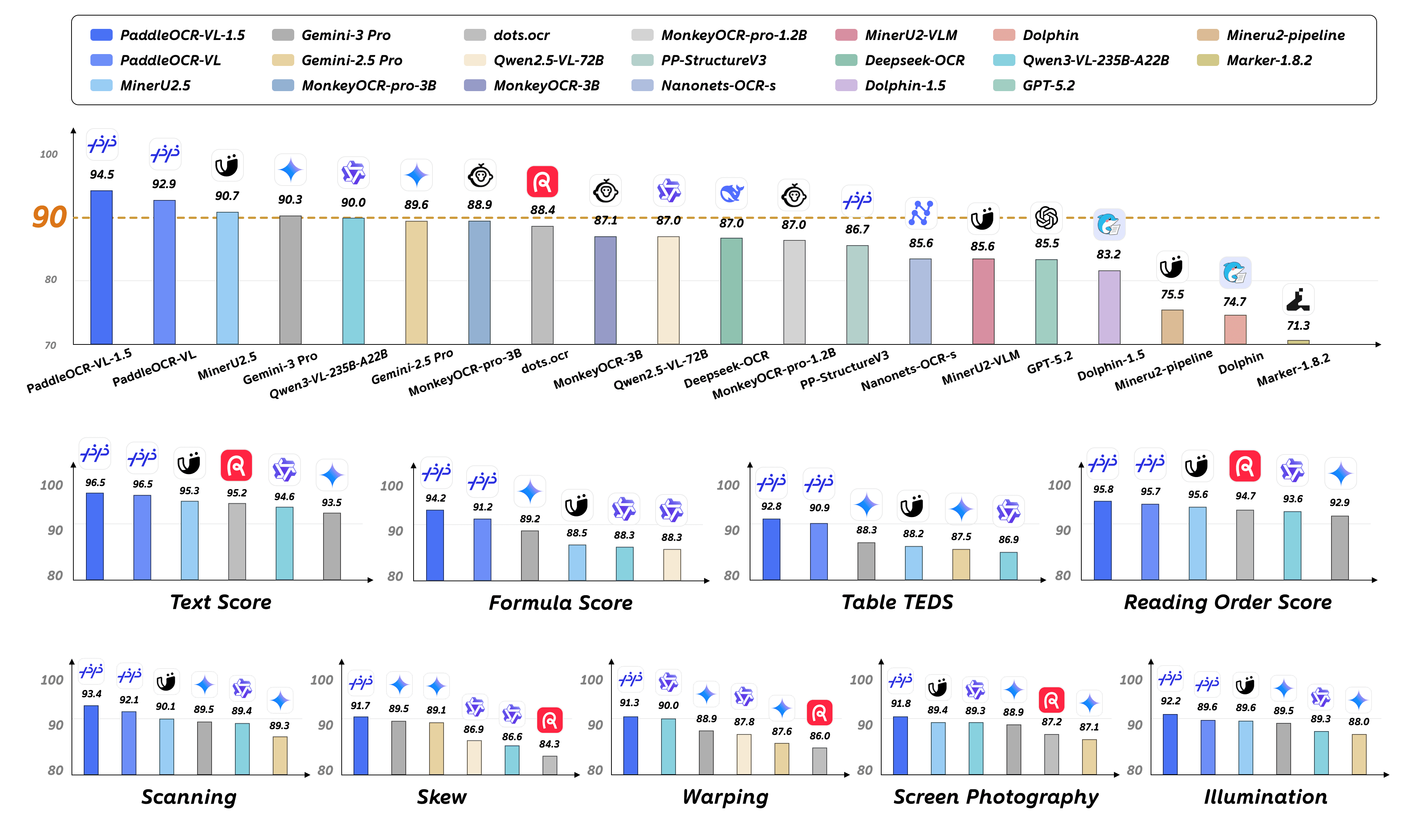
The latest release of PaddlePaddle's optical character recognition suite spans models from 1.5M to 34.5M parameters under an Apache 2.0 license.
An open, autoregressive text-to-speech model targets English and Spanish under a permissive Apache 2.0 license.
InclusionAI's new mixture-of-experts model bets that agent-horizon scaling can rival far larger systems on long-running tasks.
2 releases
A compact, MIT-licensed 9B model built for autonomous coding tasks arrives on Hugging Face.
An MIT-licensed mixture-of-experts model targets self-scaffolding code tasks without the footprint of a frontier system.
1 release
The compact, code-focused language model arrives on Hugging Face under an open model license.
2 releases
Datalab's new open vision-language model targets structured data extraction from documents, turning messy PDFs into clean JSON.
The Chinese tech giant's multilingual vision-language model targets text extraction across languages and document types.
3 releases
The Cohere Labs transcription model targets Arabic and English audio under a permissive open license.
The image-generation startup releases its second-generation diffusion model in raw and turbo variants under open weights.
A new text-to-image model ships with a faster Turbo variant and downloadable weights on Hugging Face.
1 release
The new bilingual model from the Chinese AI firm uses a Mixture of Experts architecture and sparse attention under a fully permissive license.
2 releases
An ultra-small, experimental text-to-speech model arrives under Apache 2.0, aimed at running speech synthesis directly on local machines.
A new open-weight diffusion model for image editing ships with ComfyUI support and a permissive license that allows commercial use.
1 release
The AI coding startup steps into open weights with an Apache-2.0 mixture-of-experts model built for text and code.
1 release
A compact Qwen3-derived model built to explore repositories, released under a permissive MIT license.
1 release
The open-weights multimodal model leans into coding and agentic tasks, extending Moonshot's Kimi line into a new scale bracket.
1 release
The new 3-billion-parameter model from the Chinese tech giant focuses on challenging benchmarks in mathematics, coding, and graduate-level questions.
2 releases
The new Mixture-of-Experts model from the Chinese AI company can generate code while also understanding visual inputs, a rare combination in open models.
The new text-to-speech model offers a commercially permissive alternative for developers in a field still dominated by closed-source APIs.
3 releases
The new 26B parameter model from DeepMind uses a diffusion-based architecture, a technique more common in image generation, to produce text.
The new open-source diffusion model from the company's research arm generates video clips from a single character image and a sequence of poses.
Baidu's open-source OCR toolkit ships an Apache-licensed text-line detector in safetensors format, tuned for a balance of accuracy and speed.
1 release
The new Apache 2.0-licensed model is designed for code generation and agentic chat applications, using a Mixture-of-Experts architecture for efficiency.
3 releases
Boson AI's new text-to-speech release aims for expressive, controllable voice synthesis across multiple languages.
The new open-weights text-to-speech system targets expressive, controllable voice generation across multiple languages with built-in voice cloning.
The new 4-billion-parameter text-to-speech model is available for non-commercial use, promising fine-grained control over vocal delivery.
2 releases
A 9.3-billion-parameter text-to-image model lands on GitHub with downloadable weights and code.
A 9.3-billion-parameter text-to-image system lands with open weights and a public GitHub home.
2 releases
The new open-weight model from MiniMax AI combines vision, coding, and reasoning using a Mixture-of-Experts architecture.
The Chinese e-commerce giant has released a new model capable of generating long-form, multi-shot videos with synchronized audio from text prompts.
1 release
The new 9.3 billion parameter model uses a Diffusion Transformer architecture and excels at rendering coherent text within generated images.
1 release
The new model from the Chinese tech giant uses a Multimodal Diffusion Transformer to generate synchronized audio and video from text or image prompts.
1 release
An open-source engine generates audio on the fly at 25Hz, no cloud required.
1 release
A new text-to-speech model introduces 'delay-pattern decoding' to solve common word skipping and repetition errors in parallel generation.
2 releases
The new 12-billion-parameter open model from DeepMind introduces a unified 'any-to-any' architecture for advanced multimodal tasks.
The new 12-billion-parameter model from Google DeepMind is designed to handle a flexible mix of data types, moving beyond traditional text and image inputs.
4 releases
The latest release in NVIDIA's 'world model' research family aims to generate coherent and realistic video from a single static image.
An audio-driven avatar model that animates still images into talking video, with support for continuation of longer clips.
The compact 1B-parameter model brings long-context handling and tool-calling to phones and laptops.
The new text-to-speech system adapts the decoder-only architecture of language models like Llama to generate more natural-sounding speech.
2 releases
Researcher Zhifei Xie has released a 1.7B-parameter model that refines Alibaba's Qwen3-ASR, showing improved performance on English and Chinese transcription benchmarks.
The open-weights team behind MOSS turns to long-form speech recognition with built-in speaker diarization and timestamps.
1 release
The new model, SANA-WM, uses a bidirectional diffusion process to give creators fine-grained control over camera movement and video editing.
2 releases
The 600-million-parameter model uses a FastConformer architecture for real-time, multilingual speech-to-text applications.
The 3-billion-parameter model handles image and video generation, editing, and understanding from a single set of weights under a permissive license.
1 release
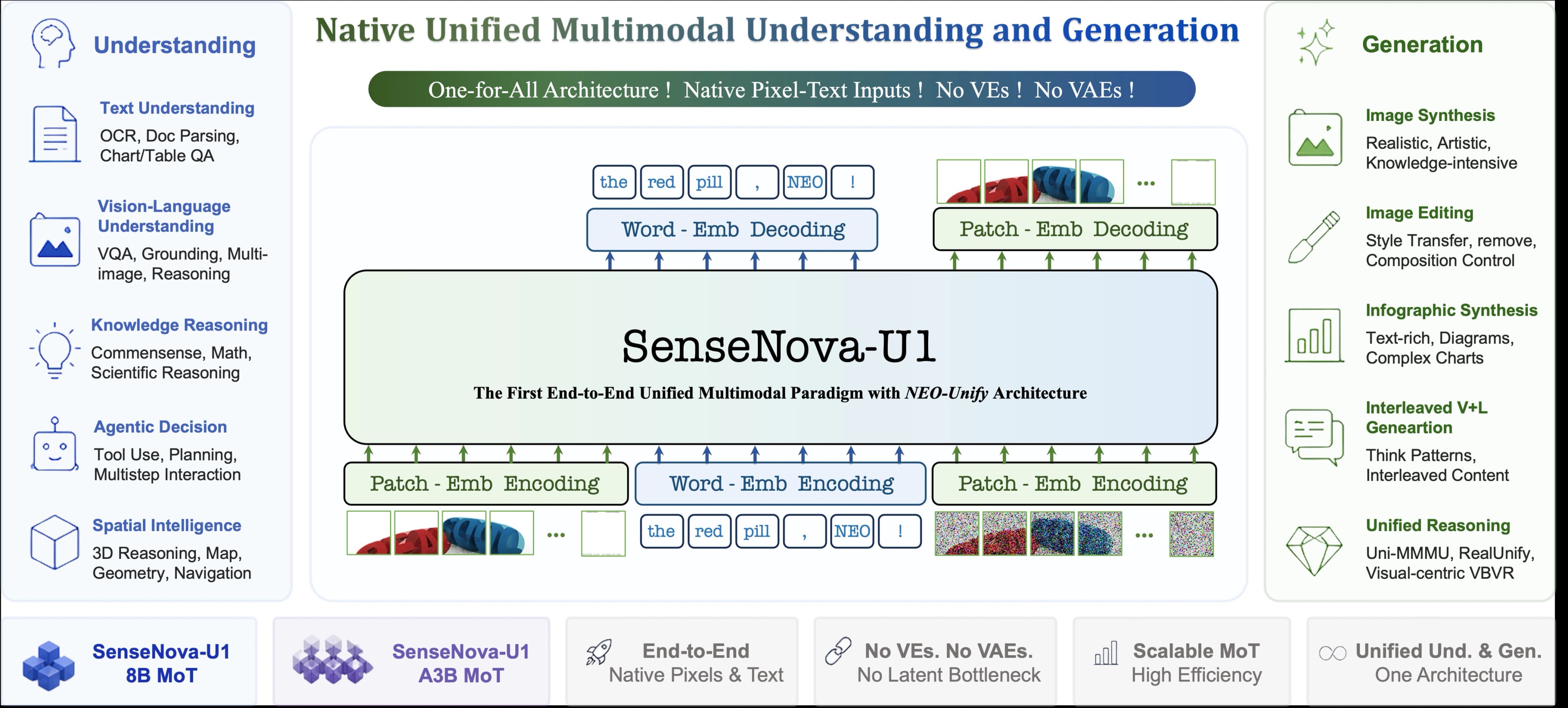
The new 8B-parameter SenseNova U1 model from SenseTime is designed for complex multimodal tasks, including the in-conversation generation and editing of infographics.
2 releases
The team behind GLiNER releases an open-source small language model aimed at making safety moderation cheaper and quicker to run.
Cactus Compute distilled Gemini's tool-calling behavior into a tiny model meant to run locally.
2 releases
The new 'Identity-Control' adapter fine-tunes the company's LTX-2.3 video model to create realistic lip-syncing for dubbing workflows.
The 1.8 billion-parameter model from the Chinese tech giant is designed for high-quality translation across a wide range of language pairs.
1 release
The new Supertonic 3 model supports seven languages and is optimized for local inference with the portable ONNX format.
1 release
LFM2.5-Embedding-350M targets retrieval and search workloads on edge hardware, where compact size matters as much as accuracy.
1 release
Moonshot AI's open-weights mixture-of-experts model reportedly outperformed Claude, GPT-5.5, and Gemini on a programming challenge.
1 release
The new component is a specialized VAE decoder that works with Stability AI's Z-Image model to enhance super-resolution tasks.
1 release
The new 30-billion parameter Mixture-of-Experts model handles text and images while using only 3 billion active parameters for inference.
5 releases
The new 26-billion-parameter model from DeepMind uses a mixture-of-experts design for greater efficiency and is tuned for assistant-style tasks.
The new 31-billion-parameter model is an instruction-tuned, 'any-to-any' powerhouse released under a permissive Apache 2.0 license.
The new 4-billion-parameter model is instruction-tuned for 'any-to-any' tasks, handling a flexible mix of data types.
The new compact model from DeepMind is instruction-tuned for "any-to-any" tasks, capable of processing and generating mixed data types.
The new open-source model from the Chinese tech giant offers automatic speech recognition for Mandarin, Cantonese, and English under a permissive MIT license.
4 releases
The new open-source model from inclusionAI uses a Mixture-of-Experts architecture to handle multiple vision tasks in a single, diffusion-based system.
The new flagship model combines a Mixture-of-Experts architecture with a permissive MIT license, positioning it for wide commercial adoption.
The new Mixture of Experts model from the Beijing-based AI lab is optimized for fast, efficient conversational AI and carries a fully permissive license.
The new SenseNova-U1 model unifies image understanding, generation, and editing within a single 8-billion-parameter framework.
1 release
The new dense model, licensed under Apache 2.0, brings both text and image understanding to the midrange parameter space.
1 release
The new 30-billion-parameter Mixture-of-Experts model handles any combination of modalities with just 3 billion active parameters.
1 release
The new text-to-speech model uses a diffusion-transformer architecture for high-quality, expressive audio and one-shot voice cloning.
1 release
The new two-billion-parameter model offers transcription capabilities for at least five major languages under a permissive Apache 2.0 license.
1 release
The new Qwen3.6-35B-A3B from Alibaba's Qwen team combines vision and language capabilities using an efficient sparse architecture.
2 releases
The new Apache 2.0 licensed model uses a diffusion transformer architecture to offer a new open alternative for video generation research.
The Chinese AI lab has published weights for its new vision-language model, though a restrictive license limits its use to research applications.
1 release
The new open-source vision-language model is designed for high-resolution image understanding on mobile and edge devices.
2 releases
A new 30B mixture-of-experts base model activates just 3B parameters per token and pairs a hybrid diffusion/Mamba design.
An experimental 30B mixture-of-experts base model blends diffusion and Mamba ideas under a two-tower design.
1 release
The new conversational language model from the Chinese AI company uses a Mixture-of-Experts architecture and 8-bit weights, but is released under a restrictive custom license.
1 release
The large diffusion model from the Chinese tech giant is available under the commercially permissive Apache 2.0 license, a notable release for the community.
1 release
This new component is part of a novel transformer-based architecture for text-to-image generation, released under a permissive Apache 2.0 license.
2 releases
The new bilingual model from the Chinese AI firm features an efficient Mixture-of-Experts architecture and a fully permissive MIT license.
The new diffusion-based model from the OpenBMB research group supports multilingual speech, emotional control, and zero-shot voice cloning.
2 releases
The new open-source model from OpenMOSS-Team generates high-quality speech in multiple languages while maintaining a remarkably small footprint.
The new HY-Embodied 0.5 is a vision-language model designed specifically for multi-object tracking in dynamic, real-world environments.
2 releases
Built on their HunyuanVideo-1.5 architecture, the new model synthesizes video by combining multiple static images and text prompts into a cohesive narrative.
The new JoyAI-Image-Edit model allows for instruction-based photo manipulation in both English and Chinese under a permissive Apache 2.0 license.
2 releases
The gaming giant behind 'PUBG' has released Raon-Speech-9B, a multimodal model for English and Korean speech recognition and synthesis.
A new open-source text-to-speech model from the k2-fsa project can replicate a voice and generate speech in multiple languages from a single short audio sample.
1 release
The new diffusion-based model handles speech, music, and general audio tasks like conversion and editing within a single, versatile framework.
1 release
The Chinese tech company has released the weights for a unified model that can process and generate combinations of text, images, audio, and video.
1 release
The new automatic speech recognition model from Cohere Labs sets a new benchmark on the Hugging Face Open ASR Leaderboard for multilingual performance.
1 release
The 500-million-parameter model from researcher Aratako provides a high-quality, single-speaker voice under a permissive MIT license.
1 release
The new open-source model from the General Artificial Intelligence Research team can create video clips complete with audio from a variety of inputs.
1 release
The new vision-language model from the Chinese tech giant is designed for complex, multilingual optical character recognition and layout analysis.
1 release
Cactus Compute's tiny encoder-decoder is distilled specifically for function calling at the edge, trading general chat for a narrow, useful job.
2 releases
The new open-source model from DeepMind uses a Mixture-of-Experts architecture to handle both text and image inputs efficiently.
The new 31-billion-parameter model is instruction-tuned and can process both text and images, marking a significant expansion for the Gemma family.
2 releases
The new open-weight model offers a more compact, distilled version of the advanced FLUX architecture for text-to-image and editing tasks.
The new text-to-speech model can follow natural language instructions to control tone, clone voices from short clips, and speak multiple languages.
1 release
The new model, based on Stable Video Diffusion, can create video and a corresponding soundtrack simultaneously from text, image, or audio prompts.
6 releases
The new 3-billion-parameter model, based on the company's Eagle architecture, is designed for high-precision visual grounding tasks.
The new 2-billion-parameter model from Google DeepMind brings efficient image-and-text understanding to the open-source Gemma family.
The new 2-billion-parameter model from DeepMind can process text, vision, and audio, making it a versatile and efficient foundation for developers.
The new 4-billion-parameter vision-language model brings image and text understanding to Google's popular open-source family.
The new 4-billion parameter model from Google DeepMind is designed for versatile input and output, handling text, images, and other data types.
The new open-source model from Xiaomi's FireRedTeam leverages the Qwen-Image-Edit pipeline to offer instruction-based image editing in both English and Chinese.
1 release
The new 800-million-parameter model is the smallest in the Qwen3.5 family, designed for efficient multimodal tasks on consumer-grade hardware.
3 releases
The new Apache 2.0-licensed model is part of the company's Granite family and aims to provide high-quality speech-to-text across several languages.
The new Qwen3.5-4B model combines text and image understanding in a compact, permissively licensed package for developers.
The new open-source vision-language model from Alibaba's Qwen team offers strong performance in a compact, Apache 2.0-licensed package.
4 releases
Resemble AI releases MIT-licensed speech-to-text models that claim higher accuracy than OpenAI's Whisper Large v3.
The new Qwen3.5-122B-A10B combines a massive parameter count with an efficient Mixture-of-Experts architecture for advanced vision and language tasks.
The new model from Alibaba's Qwen team combines multimodal understanding with a 131K token context window under a permissive Apache 2.0 license.
The new Qwen3.5-35B-A3B model from Alibaba combines vision and language capabilities with a resource-friendly Mixture of Experts design.
2 releases
The new open-source model from Alibaba uses a Mixture-of-Experts architecture to balance massive scale with efficient inference.
The new model, Tada-3B-ML, is designed for fine-grained control over vocal expression across more than 10 languages.
2 releases
An independent researcher has released a new English text-to-speech model under a permissive license, built on a modern generative foundation.
The Chinese AI company's first open-weight release uses an efficient FP8 data type but comes with a restrictive, non-commercial license.
1 release
The new Mixture-of-Experts model from the Chinese AI company combines an advanced architecture with a fully permissive MIT license for commercial use.
2 releases
The new open-source Mixture-of-Experts model can process and generate content across text, images, and audio in any combination.
The new Llama-based model was trained from scratch on 3.5 trillion tokens of Chinese and English data to enhance its bilingual capabilities.
2 releases
The new system from the OpenMOSS Team uses a novel 'delay-pattern' architecture to generate natural-sounding speech in Chinese, English, and Japanese.
The new model, SoulX-Singer, can replicate a singing voice from a short audio sample and supports both English and Chinese under a permissive license.
1 release
The new MiniCPM-o 4.5 model from the open-source research group can process and generate interleaved combinations of images, text, and audio.
1 release
The new model from OpenBMB supports mixed-modality inputs and outputs, from text and images to audio and video, in a single efficient package.
2 releases
The new model from Alibaba's Qwen team uses a Mixture-of-Experts architecture and is released under the commercially-friendly Apache 2.0 license.
The new vision-language model from the creators of the GLM series is specialized for recognizing and extracting text from images across multiple languages.
7 releases
The open-weight text-to-image model brings a 9-billion-parameter base release to the FLUX.2 Klein family.
The new open model can generate high-definition video with synchronized audio from a flexible combination of text and image prompts.
The new PaddleOCR-VL model is built to parse not just text, but also the tables, formulas, and page layouts found in complex documents.
The new model generates 360p video from text or images and creates corresponding audio tracks simultaneously, a notable step for integrated audiovisual synthesis.
The new open-source tool, based on the Qwen3 architecture, precisely synchronizes audio recordings with their corresponding text transcripts.
Alibaba's Qwen team has released a new 1.7-billion-parameter model designed specifically for automatic speech recognition.
The new 600-million-parameter Qwen3-ASR model is designed for efficient, high-quality audio transcription under a permissive license.
1 release
The new open vision-language model is designed to extract text and understand structure from complex, multilingual documents.
1 release
The new open-source world model from researcher robbyant generates short video clips from a single image, giving users control over the virtual camera path.
1 release
The makers of the popular Qwen language models have published their first open-source text-to-image generator with a permissive Apache 2.0 license.
1 release
The new text-to-speech model is optimized for the ONNX runtime, making it a promising option for efficient, on-device audio generation.
6 releases
The company, known for its powerful text models, has released its first open-source speech recognition system designed for real-time, multilingual transcription.
The new open-source automatic speech recognition model handles multilingual transcription and speaker identification out of the box.
The new 600-million-parameter Qwen3-TTS model can generate speech in multiple languages and clone voices from short audio clips.
The new 600-million-parameter model from Alibaba's Qwen team can clone voices from short audio clips for multilingual speech synthesis.
Alibaba's Qwen team has released a new text-to-speech model capable of cloning voices from just a few seconds of audio.
The new 1.7-billion-parameter text-to-speech model from Alibaba's Qwen team can generate novel voices from short audio prompts.
1 release
The new Mixture-of-Experts model from the Beijing-based AI company is optimized for speed and released under the permissive MIT license.
1 release
The new vision model from the Paris-based AI lab uses Mistral architecture to extract text and structure from complex documents like PDFs and forms.
6 releases
The new text-to-image model emphasizes speed and efficiency with a novel architecture and FP8 quantization.
The new 80-million-parameter text-to-speech model adapts a powerful language model architecture for efficient, open-source audio generation.
The new 4-billion-parameter model is a distilled version of the powerful FLUX.2 architecture, released under a commercially-friendly Apache 2.0 license.
The new 4-billion-parameter model from Black Forest Labs offers an efficient, transformer-based alternative to latent diffusion for image generation.
The new 9-billion-parameter model uses a Diffusion Transformer architecture, promising higher performance than existing open-source alternatives.
The new 9-billion-parameter text-to-image model uses a novel architecture that operates directly on pixels for faster, more efficient generation.
2 releases
The new 1-billion-parameter model combines a Llama 3.2 base with text-to-speech to generate more natural and nuanced audio.
The new 4B-parameter model is an instruction-tuned variant of Gemma, designed specifically for high-quality multilingual translation tasks.
1 release
The new text-to-speech model uses a hybrid diffusion and autoregressive architecture for high-quality, multilingual synthesis.
1 release
The new text-to-image model is fluent in both Chinese and English, built on the CogView2 architecture and released under a permissive MIT license.
1 release
The new 4-billion-parameter vision-language model is specialized for tasks in radiology, pathology, and complex clinical reasoning.
1 release
The new text-to-speech model from the audio AI company supports English, Korean, and Spanish and comes in the efficient ONNX format for deployment.
1 release
The new diffusion model from the creative app company can generate short video clips from text, images, audio, and even other videos.
1 release
The new vision-language model from the Chinese AI firm uses a Mixture-of-Experts architecture and is now available on Hugging Face.
1 release
Alibaba's latest text-to-image generator, Qwen-Image 2512, is optimized for creating visuals from both English and Chinese prompts.
1 release
The 8-billion-parameter model from Alibaba's Qwen team understands and generates spoken responses, enabling more natural audio-first applications.
1 release
The new Mixture of Experts model from the Chinese AI firm uses 8-bit floating-point precision for a smaller memory footprint and faster inference.
1 release
The new speech recognition model from DeepMind is trained specifically on medical dictation, aiming for higher accuracy in clinical notes.
4 releases
A new text-to-speech model from OpenMOSS leverages the Qwen2 architecture to generate speech in both English and Chinese.
Developer 'ekwek' has released a compact 80-million-parameter text-to-speech model, notable for its unconventional use of a Qwen3 language model architecture.
The new diffusion model from Alibaba's team allows for precise, instruction-based image modifications in both English and Chinese.
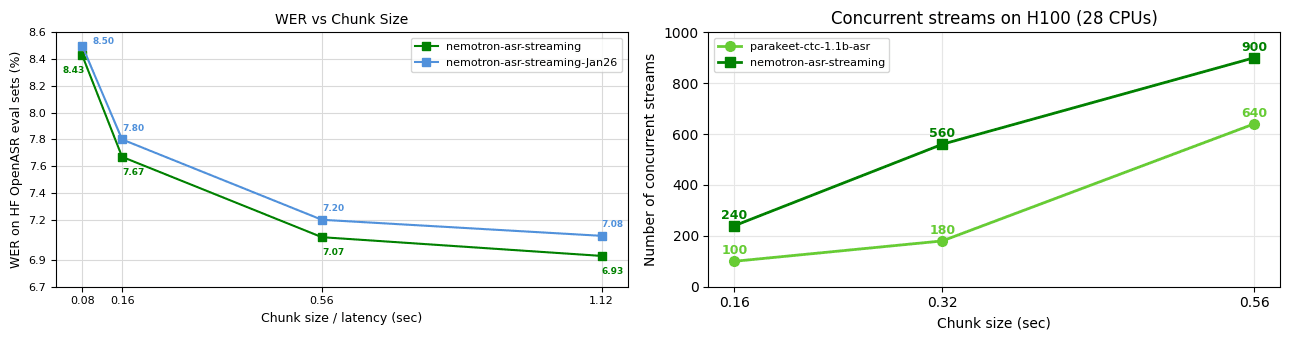
The 600-million-parameter Nemotron model is designed for real-time English transcription using a cache-aware FastConformer architecture.
1 release
The new Fun-ASR-Nano model from Alibaba's team packs real-time multilingual transcription, speaker diarization, and hotword detection into an efficient package.
1 release
The new open-source model from OpenBMB uses a diffusion-based architecture to generate expressive video from a single still image.
1 release
The new model from Tencent's Hunyuan team generates dynamic video and reconstructs 3D environments using a single static picture.
1 release
The new 500-million-parameter text-to-speech model from the Qwen team offers multilingual voice cloning and emotional control.
1 release
This new text-to-speech model can replicate a voice from just a few seconds of audio, using a novel combination of flow matching and reinforcement learning.
1 release
The new GLM-ASR-Nano model is designed for efficient automatic speech recognition in both English and Mandarin Chinese.
1 release
The new model from the GLM-4.6V family offers a fast, MIT-licensed option for developers working with both text and images.
2 releases
The new 500-million-parameter text-to-speech model from OpenBMB supports both English and Chinese and can replicate a voice from a short audio sample.
The new LongCat-Image-Edit model follows natural language instructions to perform complex photo manipulations in both English and Chinese.
2 releases
The new 14-billion-parameter model uses audio input to generate realistic talking head videos from a single still image.
The new 500-million-parameter model is designed for generating natural, long-form speech with very low latency for interactive applications.
1 release
The new text-to-speech model focuses on performance and offers voice cloning capabilities for English under a permissive MIT license.
1 release
The new Mixture-of-Experts model from DeepSeek AI combines an efficient FP8 architecture with a fully permissive license for commercial use.
1 release
The new 4-billion-parameter model handles text, image, and speech inputs and outputs, including direct speech-to-speech translation.
1 release
The new text-to-image model from the team behind Qwen uses a diffusion transformer to generate high-resolution images in just a single step.
1 release
The developer preview of the next-generation text-to-image architecture promises significant architectural improvements over its predecessor.
2 releases
The new diffusion model generates short video clips from text and image prompts, adding another major player to the open video space.
The new vision-language model from Tencent Hunyuan offers a compact, end-to-end solution for optical character recognition.
1 release
The French AI leader expands beyond large language models with a new, 4-billion-parameter model for generating multilingual speech.
1 release
The 2-billion-parameter text-to-speech model can clone voices from a short audio sample and is available under an Apache 2.0 license.
2 releases
The latest Segment Anything Model extends Meta's mask-generation lineage from still images into video, now available on Hugging Face.
The new ERNIE 4.5 VL model brings advanced multimodal reasoning to the open-source community with an efficient Mixture-of-Experts architecture.
1 release
The new Mixture-of-Experts model is designed for complex tasks but arrives in a custom compressed format with a restrictive license.
1 release
The new open-source model from the Allen Institute for AI unifies text and image understanding and generation into a single architecture.
1 release
The 7-billion-parameter model is designed to understand and interact with graphical user interfaces, building on Alibaba's open-source Qwen2.5-VL.
1 release
The new 1.7 billion-parameter model from OpenMOSS is trained on conversational data to generate natural dialogue in English and Chinese.
1 release
The Chinese tech giant has released a new MIT-licensed model capable of generating video from text, images, or by continuing existing clips.
1 release
The new open-source Mixture-of-Experts model can process and generate any combination of text, images, video, audio, and 3D data.
2 releases
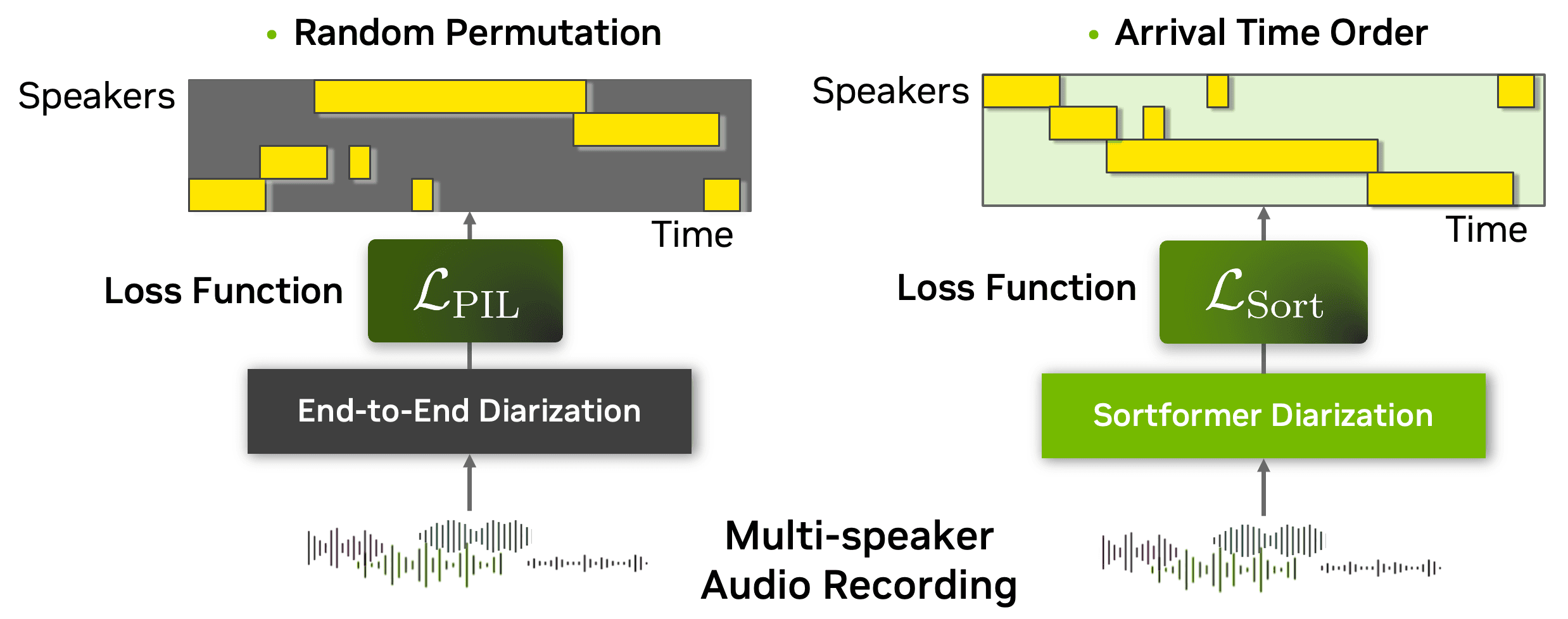
The new Sortformer-based model is designed for streaming audio, identifying up to four distinct speakers in real time.
The Shanghai-based AI startup has released a new Mixture-of-Experts model focused on complex reasoning, coding, and agentic tasks.
1 release
The new vision-language model from Datalab is fine-tuned from Qwen2-VL to specialize in extracting text and structure from complex documents.
2 releases
The new open-source model combines both video generation and comprehension, a rare dual capability built on the Qwen2.5 vision-language foundation.
The new Apache 2.0 licensed model uses a Llama-based architecture to generate more natural and emotionally nuanced speech from text.
1 release
The new vision-language model uses a novel context compression technique to efficiently extract text and structure from complex documents.
1 release
The new vision-language model is fine-tuned to understand not just text, but the complex structure of tables, charts, and formulas.
1 release
The 600-million-parameter model offers real-time speech-to-text with speaker diarization, built on the efficient FastConformer architecture.
1 release
The new Ming-flash-omni-Preview aims to handle any combination of data modalities using an efficient Mixture of Experts architecture.
1 release
The latest vision-language model from the popular Qwen series is instruction-tuned and available under an Apache 2.0 license.
3 releases
The new 270-million-parameter model from Google DeepMind is fine-tuned specifically for reliable function calling and tool use.
The new open-source model from Swiss researchers uses a novel chunking method to generate indefinitely long videos from a single still image.
The new 14-billion-parameter model is a distilled, more efficient version of a larger foundation, designed for interactive video generation.
4 releases
The new 16-billion-parameter model uses a sparse Mixture-of-Experts design to efficiently handle 'any-to-any' data combinations, from text to images.
The new open-source model from Alibaba uses a Mixture-of-Experts architecture to make its powerful vision-language capabilities more efficient to run.
Based on the Language-Free Modeling for Multilingual Text-To-Speech (LFM2) architecture, the new model offers an efficient solution for developers.
Built on the Wan2.2 architecture, this new 5-billion-parameter model generates short video clips from a single image and simultaneously creates synchronized audio.
2 releases
The new Mixture-of-Experts model is available under a permissive MIT license and is optimized for complex reasoning and coding tasks.
A new 16-billion-parameter model from inclusionAI uses a Mixture-of-Experts architecture to handle a wide range of audio tasks efficiently.
1 release
The new model from the TikTok parent company generates short video clips that maintain a person's likeness from a single reference image.
2 releases
The new text-to-image generator from the Chinese tech giant uses a Mixture-of-Experts architecture for more efficient and detailed image creation.
The new text-to-image generator from the Chinese tech giant uses a Mixture-of-Experts architecture for improved efficiency and output quality.
1 release
The new model from Alibaba's Qwen team allows users to modify images using natural language prompts instead of complex tools or masks.
1 release
The new 30B Mixture-of-Experts model from Alibaba's Qwen team can process and generate content across text, image, and audio formats.
1 release
This new instruction-tuned model from Xiaomi can handle a flexible combination of audio and text inputs and outputs, from transcription to voice synthesis.
1 release
The new 500-million-parameter model offers high-quality text-to-speech and zero-shot voice cloning under a permissive license.
3 releases
The new 30-billion-parameter Mixture-of-Experts model from Alibaba's Qwen team is designed to show its reasoning process for complex multimodal tasks.
The new Mixture-of-Experts model from Alibaba is fine-tuned to generate detailed, multilingual descriptions for complex audio content.
The new Apache 2.0 text-to-speech model is built on a Qwen2 architecture and optimized for local inference with GGUF support.
1 release
The next generation of the efficient, open-source vision-language model is now available for early testing and feedback.
2 releases
The new open-source model specializes in creating realistic videos of people, separating appearance from motion for greater control.
The new 14-billion-parameter model from Alibaba's PAI team offers fine-grained control over video generation using inputs like sketches and depth maps.
2 releases
The new Qwen3-Next model from Alibaba combines a large parameter count with an efficient MoE architecture to balance performance and computational cost.
This new open-source model uses a diffusion architecture instead of a typical transformer to generate and understand a mix of media types.
1 release
The new text-to-image model uses a novel rejection sampling technique to align Stable Diffusion XL more closely with human aesthetic preferences.
1 release
The new text-to-image model from the Chinese tech giant is designed to understand both Chinese and English prompts at high resolutions.
2 releases
The new 7-billion-parameter model is designed for generating long-form, multi-speaker audio in English and Chinese under a permissive MIT license.
The new open-source model specializes in generating long-form, multi-speaker audio in both English and Mandarin, mimicking a natural podcast conversation.
1 release
The new open-source model handles both speech recognition and audio generation in a single, end-to-end architecture.
1 release
The new model from Tencent AI Lab generates temporally and spatially consistent video sequences from a single image, enabling virtual exploration of static scenes.
2 releases
The new 1.5-billion-parameter text-to-speech model is designed to generate natural, multi-speaker audio for podcasts and other long-form content.
The new Wan2.2-S2V model takes a still image and a speech track to generate a realistic talking-head animation, available under a permissive license.
1 release
The new vision-language model from the open-source research group demonstrates strong OCR and video understanding capabilities in a small package.
1 release
The new DeepSeek-V3.1-Base is a massive 671-billion-parameter Mixture-of-Experts model designed for efficient, large-scale research and development.
1 release
The new open-source model from Alibaba lets users edit images with simple text commands in both English and Chinese.
1 release
The new 4-billion-parameter model is designed for 'any-to-any' multimodal tasks and optimized to run efficiently on mobile hardware.
1 release
The new Hunyuan-GameCraft 1.0 is an open image-to-video model that generates interactive game-like scenes with precise camera control.
1 release
A new diffusion-based model from developer FrancisRing animates still images into talking avatars using only an audio track.
1 release
The new Mixture-of-Experts model offers strong multimodal reasoning capabilities under a permissive MIT license.
1 release
The new 1.3-billion-parameter model functions as an interactive 'world model,' generating controllable video scenes from a single static image.
1 release
The new ultra-compact model from DeepMind is designed for efficient performance in resource-constrained environments like mobile and web.
4 releases
The new `gpt-oss-20b` is an Apache 2.0-licensed Mixture-of-Experts model designed to run efficiently on consumer-grade hardware.
The new 117-billion-parameter `gpt-oss-120b` is a Mixture-of-Experts model focused on reasoning, released under a permissive Apache 2.0 license.
The new 1-billion-parameter model handles both transcription and translation across five languages using the company's efficient FastConformer architecture.
The new FastConformer model uses a specialized training technique to improve transcription accuracy in noisy, real-world environments.
1 release
The new Apache 2.0 diffusion model from Alibaba's Qwen team focuses on accurately rendering both English and Chinese characters within generated images.
1 release
The new Apache 2.0 model from Alibaba's Qwen team uses a Mixture-of-Experts architecture to deliver strong performance with only 3B active parameters.
1 release
The new 3B-parameter model from rednote-hilab uses a vision-language approach to parse tables, layouts, and even mathematical formulas.
1 release
The new autoregressive model from the Chinese AI lab can understand, generate, and edit images within a single, compact framework.
3 releases
The new open-source diffusion model from the team behind Qwen uses a Mixture-of-Experts architecture to animate still images.
The new Apache 2.0-licensed generator uses a Mixture-of-Experts architecture and is available in the popular Diffusers library format for easier integration.
The new Apache 2.0 licensed model from Alibaba's team generates video from either text prompts or still images, offering a unified approach in a compact package.
2 releases
The new Apache 2.0-licensed model from Alibaba's team uses a Mixture-of-Experts architecture for efficient, high-quality video generation.
The new 14-billion parameter model from Alibaba's AI team uses a Mixture-of-Experts design and is available under the permissive Apache 2.0 license.
1 release
The new flagship coding model from Alibaba's Qwen team uses a massive Mixture-of-Experts architecture and is released under a permissive Apache-2.0 license.
1 release
The new Mixture-of-Experts model combines massive scale with a fully permissive license, targeting complex reasoning and agentic applications.
1 release
The new Apache 2.0 licensed model from Alibaba's team can generate video from both text and image prompts, adding a powerful new tool to the open-source creative ecosystem.
1 release
The new MIT-licensed model, HiDream-E1.1, allows for complex image modifications by following natural language instructions.
1 release
The new MIT-licensed model from inclusionAI can process and generate a mix of text, images, audio, and video, pushing the boundaries of open multimodal AI.
2 releases
Based on the Wan2.1 architecture, this new 14B parameter model offers fine-grained control over video generation from still images and text.
The new streaming Conformer model from the Russian digital bank is optimized for real-time transcription of telephone conversations.
1 release
The new Mixture-of-Experts model brings massive scale to the open-weights community, focusing on complex reasoning and coding tasks with a 128K context window.
1 release
The new 12-billion-parameter model, tuned by creative AI platform Krea, focuses on high-quality aesthetic output and prompt fidelity.
1 release
The new 7-billion-parameter model from the company's SEED team can process and generate a mix of text, images, audio, and video in a single unified framework.
1 release
The new 3-billion-parameter model focuses on generating expressive, multilingual speech and is fully open for commercial use under an Apache 2.0 license.
1 release
The French AI lab's new open-source model generates streaming audio in English and French under a permissive license.
2 releases
The new GLM-4.1V-9B-Thinking model makes its vision and chain-of-thought reasoning capabilities available under a permissive MIT license.
The new 3-billion-parameter model from AIDC-AI combines vision-language understanding and image generation into a single 'any-to-any' framework.
1 release
The 2.5 billion-parameter speech model combines a FastConformer encoder with a Qwen LLM decoder, a hybrid approach to transcription.
1 release
Maya Research has released a 3-billion-parameter model designed to generate natural-sounding speech in Hindi and English.
1 release
The new 7-billion-parameter model from FreedomIntelligence can process various inputs and generate or edit images based on text prompts.
1 release
A 3.5B-parameter SDXL derivative aims to become the go-to foundation for anime-style text-to-image fine-tunes.
1 release
Black Forest Labs' 12B rectified-flow model has quietly emerged as the default foundation for open image generation.










































































































































































































![FLUX.2 [dev]](/_next/image?url=https%3A%2F%2Fcdn-thumbnails.huggingface.co%2Fsocial-thumbnails%2Fmodels%2Fblack-forest-labs%2FFLUX.2-dev.png&w=3840&q=75)

















































































![FLUX.1 Krea [dev]](/_next/image?url=https%3A%2F%2Fcdn-thumbnails.huggingface.co%2Fsocial-thumbnails%2Fmodels%2Fblack-forest-labs%2FFLUX.1-Krea-dev.png&w=3840&q=75)