Thinkingmachines/Vision-Language
Thinking Machines Debuts Inkling Small, a Compact Multimodal MoE
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.
Category · other
Open any-to-any models that take and produce text, images, audio, and more in a single network — the most general open-weight systems being released.
57 releases
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.
A codec-native multimodal foundation model aims to understand live video and vision-language input in real time.
A fully open multimodal model aims to reason jointly across audio, images, and long-form video.
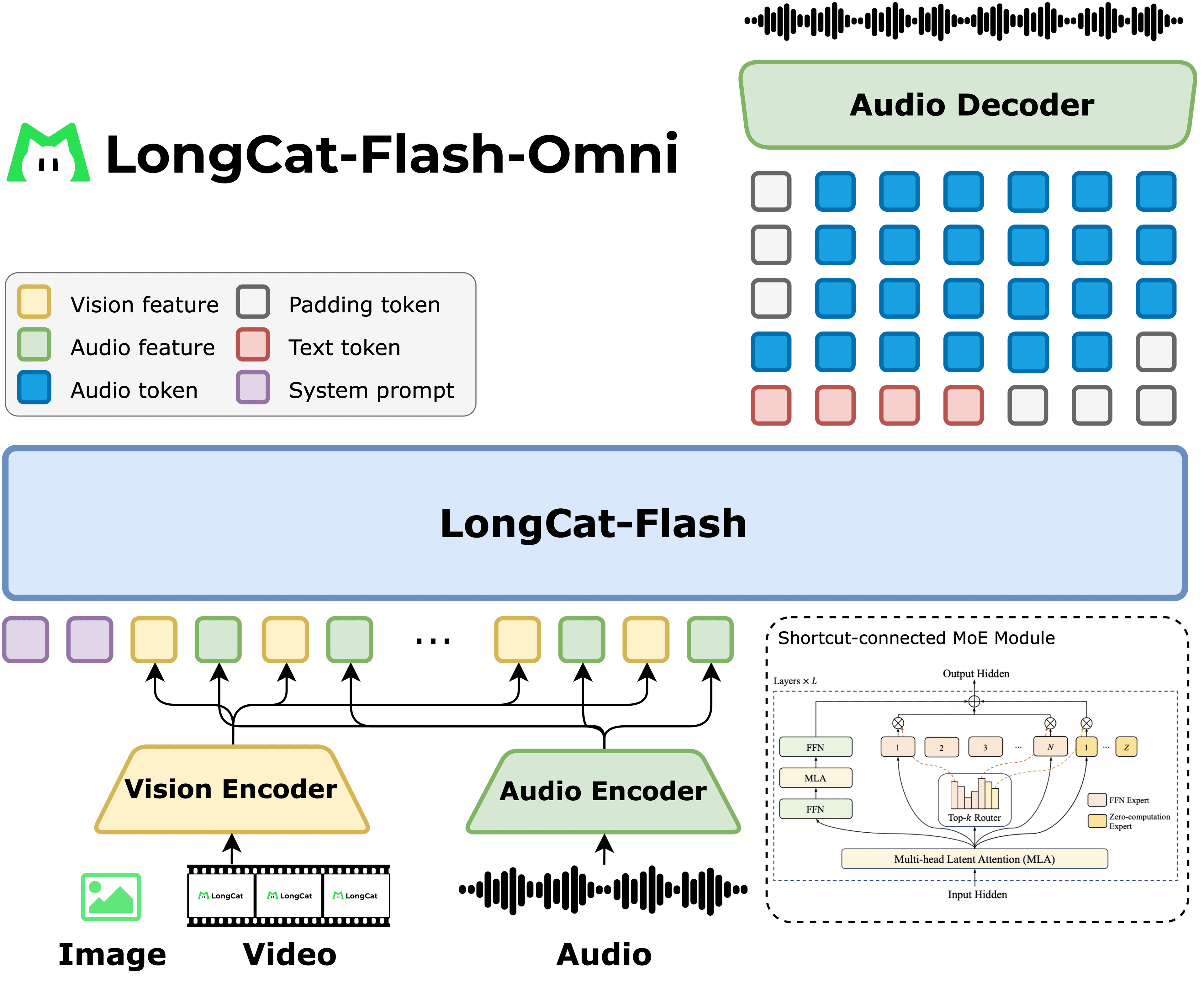
The lab's inaugural open-weights release is a mixture-of-experts system that takes image and audio inputs, shipped under a permissive Apache 2.0 license.
The Chinese research group's new vision-language model targets streaming understanding of video and images rather than static frames.
A new Apache-licensed model family folds bilingual text-to-image generation and instruction editing into one system.
A new 30B mixture-of-experts model from NVIDIA handles both listening and speaking within a single audio-text architecture.
The new open-weights family adds a mixture-of-experts design, encoder-free multimodal inputs, and an optional thinking mode.
A new foundation model brings zero-shot, in-context learning to classification and regression on structured tables.
A single 7B model from SenseTime folds vision-language understanding, image generation, editing, and perception into one system.
The new open-weight model from MiniMax AI combines vision, coding, and reasoning using a Mixture-of-Experts architecture.
The new 12-billion-parameter open model from DeepMind introduces a unified 'any-to-any' architecture for advanced multimodal tasks.
The new 12-billion-parameter model from Google DeepMind is designed to handle a flexible mix of data types, moving beyond traditional text and image inputs.
The 3-billion-parameter model handles image and video generation, editing, and understanding from a single set of weights under a permissive license.
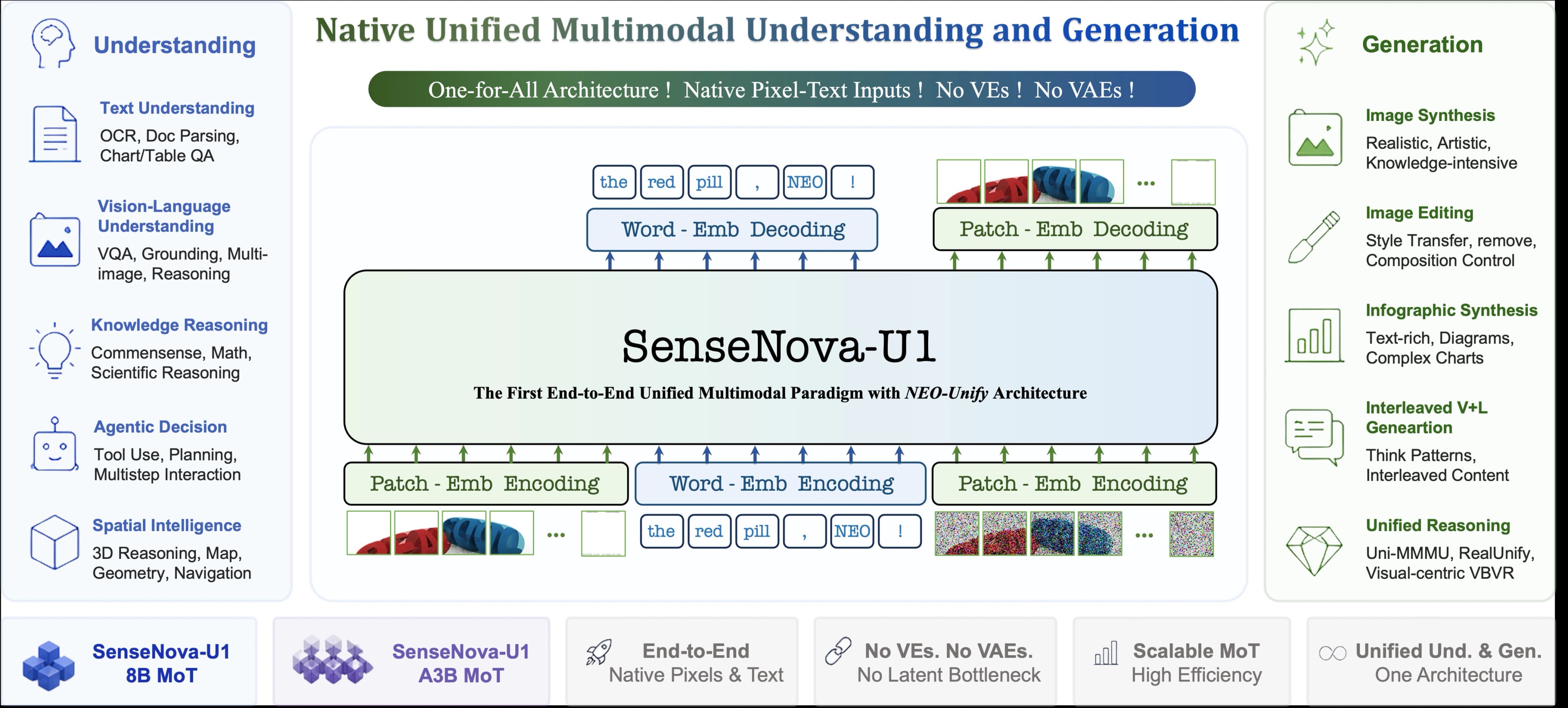
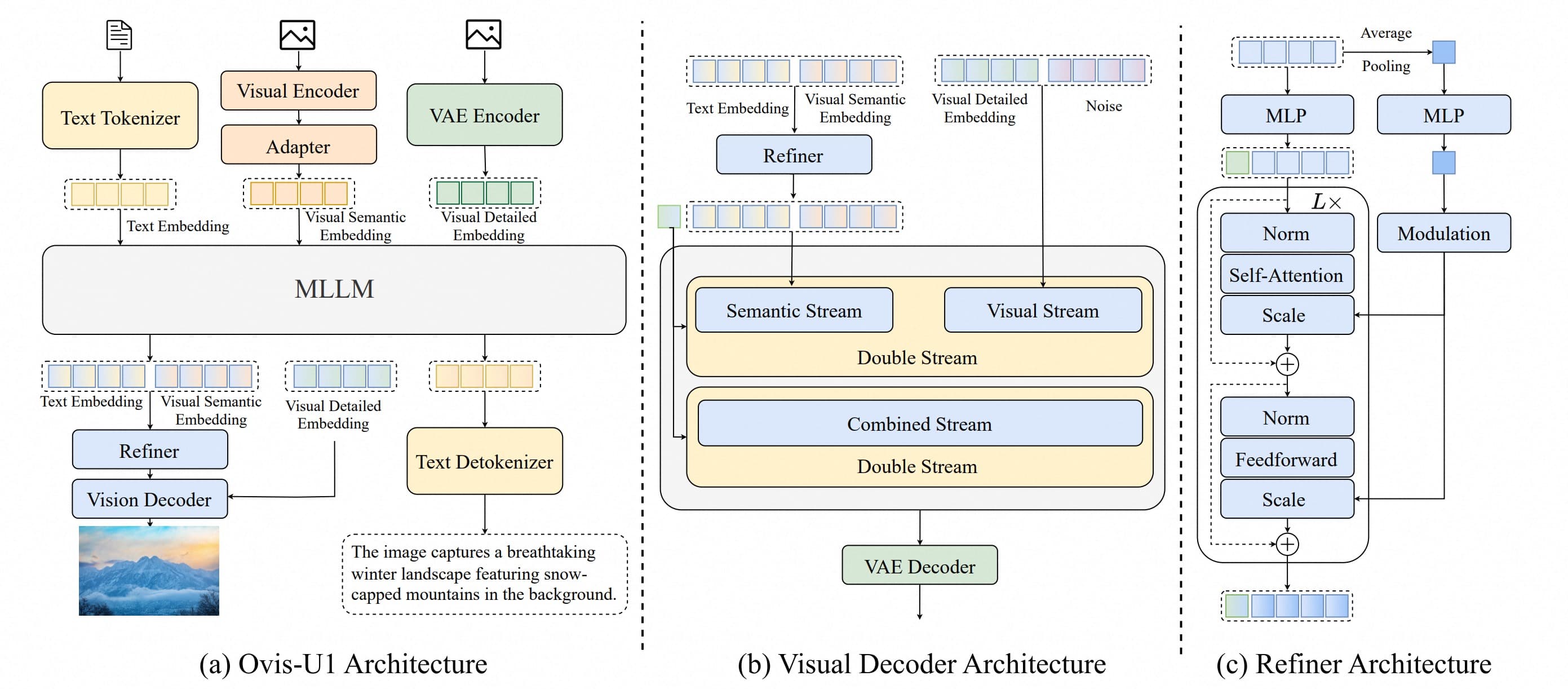
The new 8B-parameter SenseNova U1 model from SenseTime is designed for complex multimodal tasks, including the in-conversation generation and editing of infographics.
The new 30-billion parameter Mixture-of-Experts model handles text and images while using only 3 billion active parameters for inference.
The new 26-billion-parameter model from DeepMind uses a mixture-of-experts design for greater efficiency and is tuned for assistant-style tasks.
The new 31-billion-parameter model is an instruction-tuned, 'any-to-any' powerhouse released under a permissive Apache 2.0 license.
The new 4-billion-parameter model is instruction-tuned for 'any-to-any' tasks, handling a flexible mix of data types.
The new compact model from DeepMind is instruction-tuned for "any-to-any" tasks, capable of processing and generating mixed data types.
The new open-source model from inclusionAI uses a Mixture-of-Experts architecture to handle multiple vision tasks in a single, diffusion-based system.
The new SenseNova-U1 model unifies image understanding, generation, and editing within a single 8-billion-parameter framework.
The new 30-billion-parameter Mixture-of-Experts model handles any combination of modalities with just 3 billion active parameters.
The gaming giant behind 'PUBG' has released Raon-Speech-9B, a multimodal model for English and Korean speech recognition and synthesis.
The new diffusion-based model handles speech, music, and general audio tasks like conversion and editing within a single, versatile framework.
The Chinese tech company has released the weights for a unified model that can process and generate combinations of text, images, audio, and video.
The new open-source model from the General Artificial Intelligence Research team can create video clips complete with audio from a variety of inputs.
The new 2-billion-parameter model from Google DeepMind brings efficient image-and-text understanding to the open-source Gemma family.
The new 2-billion-parameter model from DeepMind can process text, vision, and audio, making it a versatile and efficient foundation for developers.
The new 4-billion-parameter vision-language model brings image and text understanding to Google's popular open-source family.
The new 4-billion parameter model from Google DeepMind is designed for versatile input and output, handling text, images, and other data types.
The new open-source Mixture-of-Experts model can process and generate content across text, images, and audio in any combination.
The new MiniCPM-o 4.5 model from the open-source research group can process and generate interleaved combinations of images, text, and audio.
The new model from OpenBMB supports mixed-modality inputs and outputs, from text and images to audio and video, in a single efficient package.
The new open model can generate high-definition video with synchronized audio from a flexible combination of text and image prompts.
The 8-billion-parameter model from Alibaba's Qwen team understands and generates spoken responses, enabling more natural audio-first applications.
The new 4-billion-parameter model handles text, image, and speech inputs and outputs, including direct speech-to-speech translation.
The new open-source model from the Allen Institute for AI unifies text and image understanding and generation into a single architecture.
The new open-source Mixture-of-Experts model can process and generate any combination of text, images, video, audio, and 3D data.
The new open-source model combines both video generation and comprehension, a rare dual capability built on the Qwen2.5 vision-language foundation.
The new Ming-flash-omni-Preview aims to handle any combination of data modalities using an efficient Mixture of Experts architecture.
The new 16-billion-parameter model uses a sparse Mixture-of-Experts design to efficiently handle 'any-to-any' data combinations, from text to images.
The new open-source model from Alibaba uses a Mixture-of-Experts architecture to make its powerful vision-language capabilities more efficient to run.
A new 16-billion-parameter model from inclusionAI uses a Mixture-of-Experts architecture to handle a wide range of audio tasks efficiently.
The new 30B Mixture-of-Experts model from Alibaba's Qwen team can process and generate content across text, image, and audio formats.
This new instruction-tuned model from Xiaomi can handle a flexible combination of audio and text inputs and outputs, from transcription to voice synthesis.
The new 30-billion-parameter Mixture-of-Experts model from Alibaba's Qwen team is designed to show its reasoning process for complex multimodal tasks.
The new Mixture-of-Experts model from Alibaba is fine-tuned to generate detailed, multilingual descriptions for complex audio content.
This new open-source model uses a diffusion architecture instead of a typical transformer to generate and understand a mix of media types.
The new open-source model handles both speech recognition and audio generation in a single, end-to-end architecture.
The new 4-billion-parameter model is designed for 'any-to-any' multimodal tasks and optimized to run efficiently on mobile hardware.
The new autoregressive model from the Chinese AI lab can understand, generate, and edit images within a single, compact framework.
The new MIT-licensed model from inclusionAI can process and generate a mix of text, images, audio, and video, pushing the boundaries of open multimodal AI.
The new 7-billion-parameter model from the company's SEED team can process and generate a mix of text, images, audio, and video in a single unified framework.
The new 3-billion-parameter model from AIDC-AI combines vision-language understanding and image generation into a single 'any-to-any' framework.
The new 7-billion-parameter model from FreedomIntelligence can process various inputs and generate or edit images based on text prompts.