Microsoft/Text → Image
Microsoft's Mage-Flow packs image editing into 4B
A compact model handles both text-to-image generation and instruction-based edits at native resolution, under a permissive MIT license.
Category · image
Open models that edit existing images from a prompt — inpainting, object removal, style transfer, and instruction-based edits, all with weights you control.
27 releases
A compact model handles both text-to-image generation and instruction-based edits at native resolution, under a permissive MIT license.
A new Apache-licensed model family folds bilingual text-to-image generation and instruction editing into one system.
A single 7B model from SenseTime folds vision-language understanding, image generation, editing, and perception into one system.
A lightweight image-editing framework claims results rivaling 10B-scale models, and it's already running in the browser.
A new open-weight diffusion model for image editing ships with ComfyUI support and a permissive license that allows commercial use.
The 3-billion-parameter model handles image and video generation, editing, and understanding from a single set of weights under a permissive license.
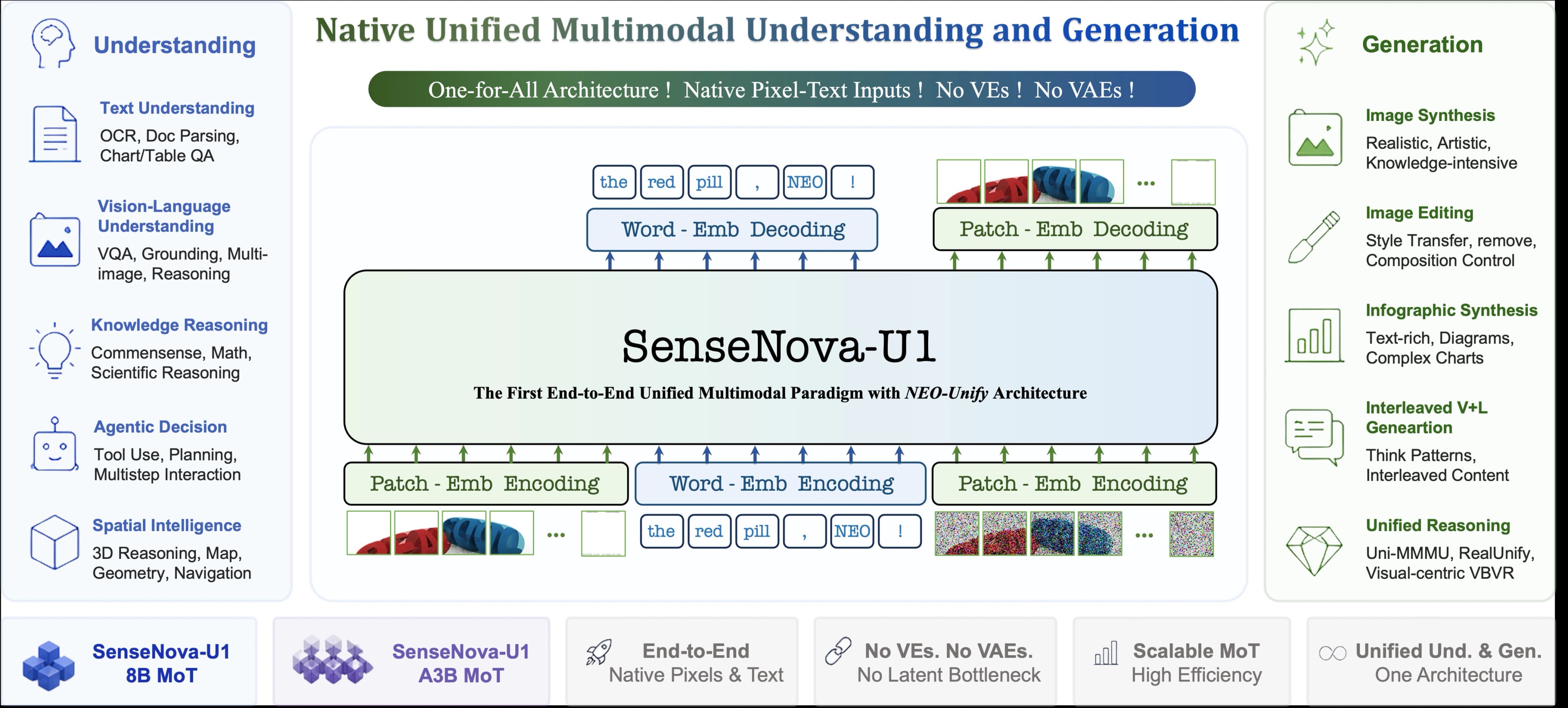
The new 8B-parameter SenseNova U1 model from SenseTime is designed for complex multimodal tasks, including the in-conversation generation and editing of infographics.
The new component is a specialized VAE decoder that works with Stability AI's Z-Image model to enhance super-resolution tasks.
The new open-source model from inclusionAI uses a Mixture-of-Experts architecture to handle multiple vision tasks in a single, diffusion-based system.
The new SenseNova-U1 model unifies image understanding, generation, and editing within a single 8-billion-parameter framework.
This new component is part of a novel transformer-based architecture for text-to-image generation, released under a permissive Apache 2.0 license.
The new JoyAI-Image-Edit model allows for instruction-based photo manipulation in both English and Chinese under a permissive Apache 2.0 license.
The new open-weight model offers a more compact, distilled version of the advanced FLUX architecture for text-to-image and editing tasks.
The new open-source model from Xiaomi's FireRedTeam leverages the Qwen-Image-Edit pipeline to offer instruction-based image editing in both English and Chinese.
The new text-to-image model emphasizes speed and efficiency with a novel architecture and FP8 quantization.
The new 4-billion-parameter model is a distilled version of the powerful FLUX.2 architecture, released under a commercially-friendly Apache 2.0 license.
The new 4-billion-parameter model from Black Forest Labs offers an efficient, transformer-based alternative to latent diffusion for image generation.
The new 9-billion-parameter model uses a Diffusion Transformer architecture, promising higher performance than existing open-source alternatives.
The new 9-billion-parameter text-to-image model uses a novel architecture that operates directly on pixels for faster, more efficient generation.
The new diffusion model from Alibaba's team allows for precise, instruction-based image modifications in both English and Chinese.
The new LongCat-Image-Edit model follows natural language instructions to perform complex photo manipulations in both English and Chinese.
The developer preview of the next-generation text-to-image architecture promises significant architectural improvements over its predecessor.
The new model from Alibaba's Qwen team allows users to modify images using natural language prompts instead of complex tools or masks.
The new open-source model from Alibaba lets users edit images with simple text commands in both English and Chinese.
The new autoregressive model from the Chinese AI lab can understand, generate, and edit images within a single, compact framework.
The new MIT-licensed model, HiDream-E1.1, allows for complex image modifications by following natural language instructions.
The new 7-billion-parameter model from FreedomIntelligence can process various inputs and generate or edit images based on text prompts.

















![FLUX.2 [dev]](/_next/image?url=https%3A%2F%2Fcdn-thumbnails.huggingface.co%2Fsocial-thumbnails%2Fmodels%2Fblack-forest-labs%2FFLUX.2-dev.png&w=3840&q=75)




