Microsoft/Text → Image
Microsoft's Mage-Flow packs image editing into 4B
A compact model handles both text-to-image generation and instruction-based edits at native resolution, under a permissive MIT license.
Category · image
Open diffusion and autoregressive image generators you can run on your own hardware — from photorealism to illustration, design, and concept art.
39 releases
A compact model handles both text-to-image generation and instruction-based edits at native resolution, under a permissive MIT license.
A new Apache-licensed model family folds bilingual text-to-image generation and instruction editing into one system.
A DMD2-distilled build of Qwen-Image trades sampling steps for speed while keeping the original model's output profile.
The image-generation startup releases its second-generation diffusion model in raw and turbo variants under open weights.
A new text-to-image model ships with a faster Turbo variant and downloadable weights on Hugging Face.
A 9.3-billion-parameter text-to-image system lands with open weights and a public GitHub home.
A 9.3-billion-parameter text-to-image model lands on GitHub with downloadable weights and code.
The new 9.3 billion parameter model uses a Diffusion Transformer architecture and excels at rendering coherent text within generated images.
The 3-billion-parameter model handles image and video generation, editing, and understanding from a single set of weights under a permissive license.
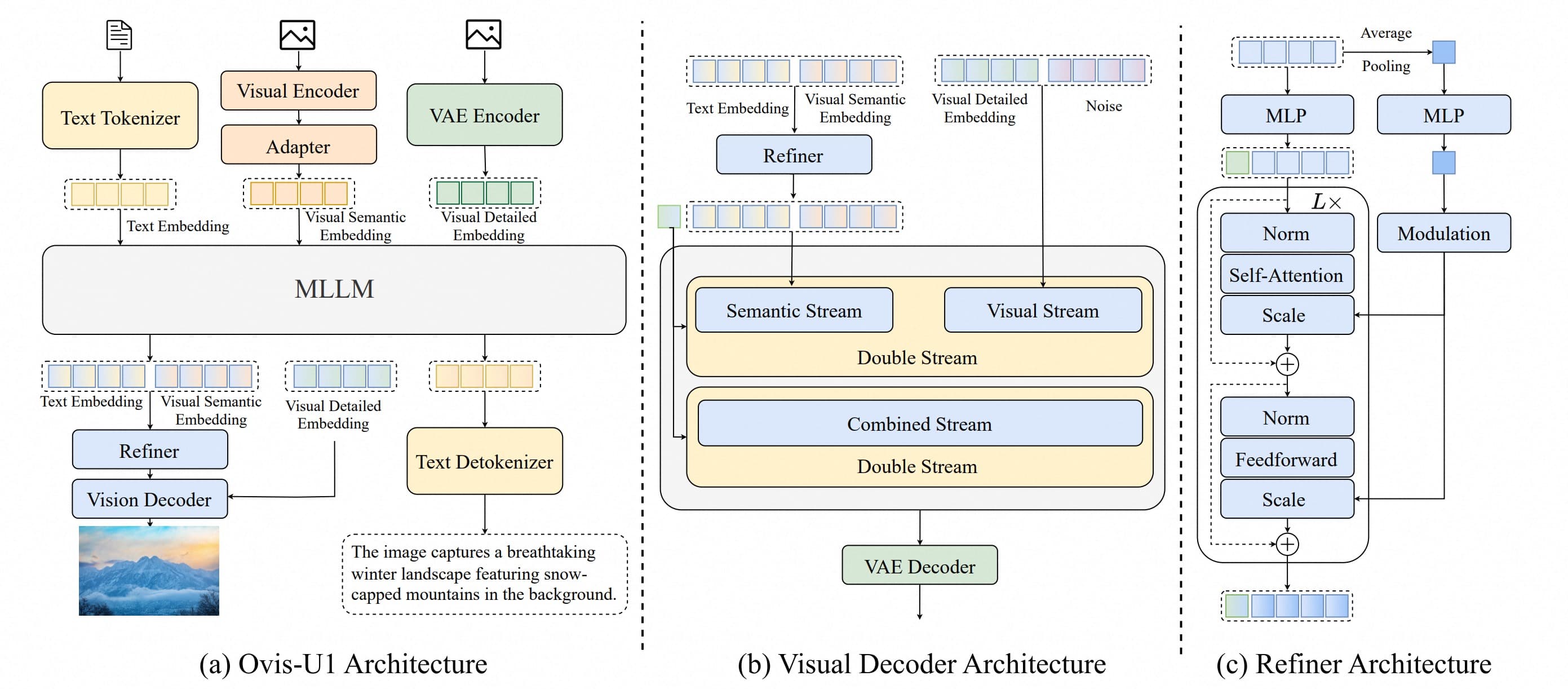
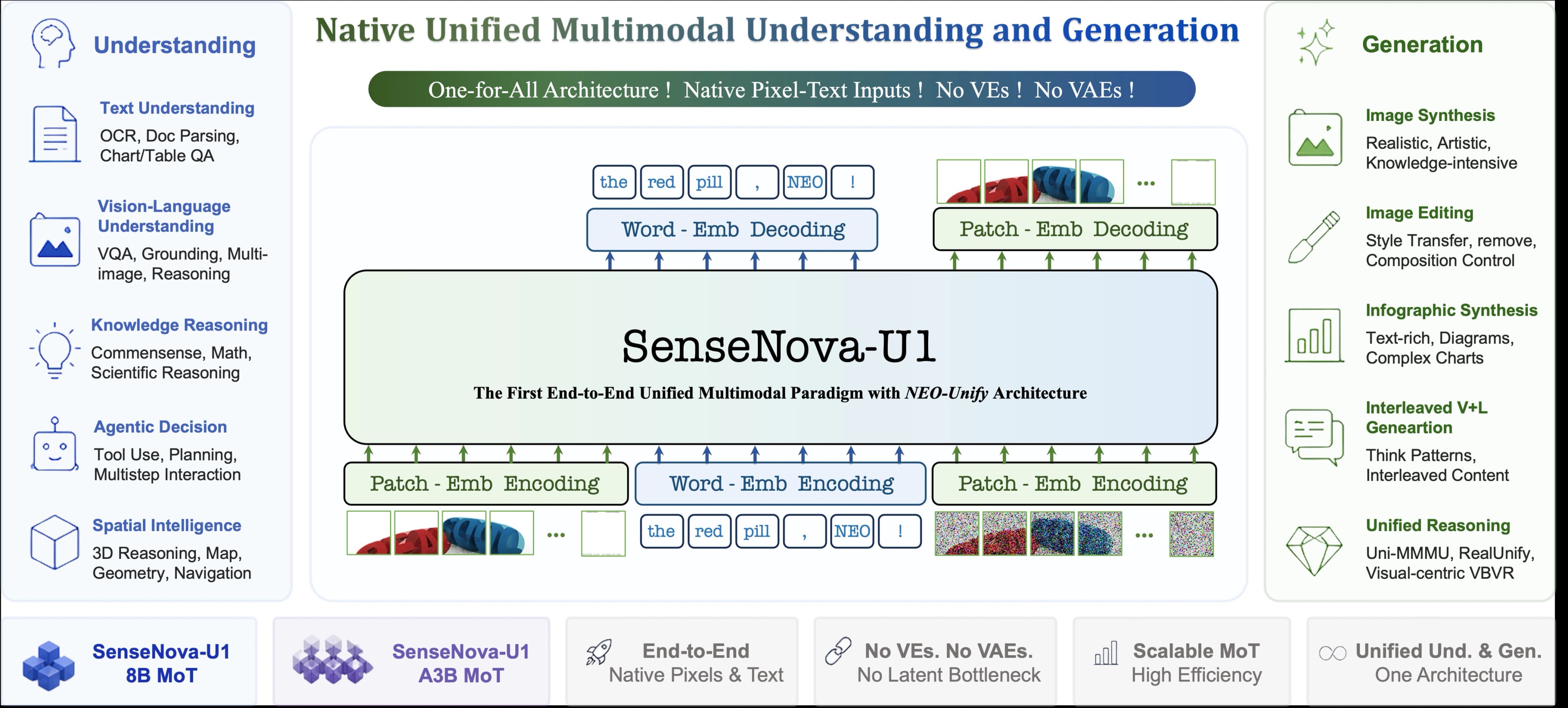
The new 8B-parameter SenseNova U1 model from SenseTime is designed for complex multimodal tasks, including the in-conversation generation and editing of infographics.
The new open-source model from inclusionAI uses a Mixture-of-Experts architecture to handle multiple vision tasks in a single, diffusion-based system.
The new SenseNova-U1 model unifies image understanding, generation, and editing within a single 8-billion-parameter framework.
The large diffusion model from the Chinese tech giant is available under the commercially permissive Apache 2.0 license, a notable release for the community.
This new component is part of a novel transformer-based architecture for text-to-image generation, released under a permissive Apache 2.0 license.
The new open-weight model offers a more compact, distilled version of the advanced FLUX architecture for text-to-image and editing tasks.
The open-weight text-to-image model brings a 9-billion-parameter base release to the FLUX.2 Klein family.
The makers of the popular Qwen language models have published their first open-source text-to-image generator with a permissive Apache 2.0 license.
The new text-to-image model emphasizes speed and efficiency with a novel architecture and FP8 quantization.
The new 4-billion-parameter model is a distilled version of the powerful FLUX.2 architecture, released under a commercially-friendly Apache 2.0 license.
The new 4-billion-parameter model from Black Forest Labs offers an efficient, transformer-based alternative to latent diffusion for image generation.
The new 9-billion-parameter model uses a Diffusion Transformer architecture, promising higher performance than existing open-source alternatives.
The new 9-billion-parameter text-to-image model uses a novel architecture that operates directly on pixels for faster, more efficient generation.
The new text-to-image model is fluent in both Chinese and English, built on the CogView2 architecture and released under a permissive MIT license.
Alibaba's latest text-to-image generator, Qwen-Image 2512, is optimized for creating visuals from both English and Chinese prompts.
The new text-to-image model from the team behind Qwen uses a diffusion transformer to generate high-resolution images in just a single step.
The developer preview of the next-generation text-to-image architecture promises significant architectural improvements over its predecessor.
The new open-source model from the Allen Institute for AI unifies text and image understanding and generation into a single architecture.
The new text-to-image generator from the Chinese tech giant uses a Mixture-of-Experts architecture for more efficient and detailed image creation.
The new text-to-image generator from the Chinese tech giant uses a Mixture-of-Experts architecture for improved efficiency and output quality.
This new open-source model uses a diffusion architecture instead of a typical transformer to generate and understand a mix of media types.
The new text-to-image model uses a novel rejection sampling technique to align Stable Diffusion XL more closely with human aesthetic preferences.
The new text-to-image model from the Chinese tech giant is designed to understand both Chinese and English prompts at high resolutions.
The new Apache 2.0 diffusion model from Alibaba's Qwen team focuses on accurately rendering both English and Chinese characters within generated images.
The new autoregressive model from the Chinese AI lab can understand, generate, and edit images within a single, compact framework.
The new 12-billion-parameter model, tuned by creative AI platform Krea, focuses on high-quality aesthetic output and prompt fidelity.
The new 3-billion-parameter model from AIDC-AI combines vision-language understanding and image generation into a single 'any-to-any' framework.
The new 7-billion-parameter model from FreedomIntelligence can process various inputs and generate or edit images based on text prompts.
A 3.5B-parameter SDXL derivative aims to become the go-to foundation for anime-style text-to-image fine-tunes.
Black Forest Labs' 12B rectified-flow model has quietly emerged as the default foundation for open image generation.


















![FLUX.2 [dev]](/_next/image?url=https%3A%2F%2Fcdn-thumbnails.huggingface.co%2Fsocial-thumbnails%2Fmodels%2Fblack-forest-labs%2FFLUX.2-dev.png&w=3840&q=75)








![FLUX.1 Krea [dev]](/_next/image?url=https%3A%2F%2Fcdn-thumbnails.huggingface.co%2Fsocial-thumbnails%2Fmodels%2Fblack-forest-labs%2FFLUX.1-Krea-dev.png&w=3840&q=75)