Ovis-U1-3B Unifies Image Understanding and Generation
The new 3-billion-parameter model from AIDC-AI combines vision-language understanding and image generation into a single 'any-to-any' framework.
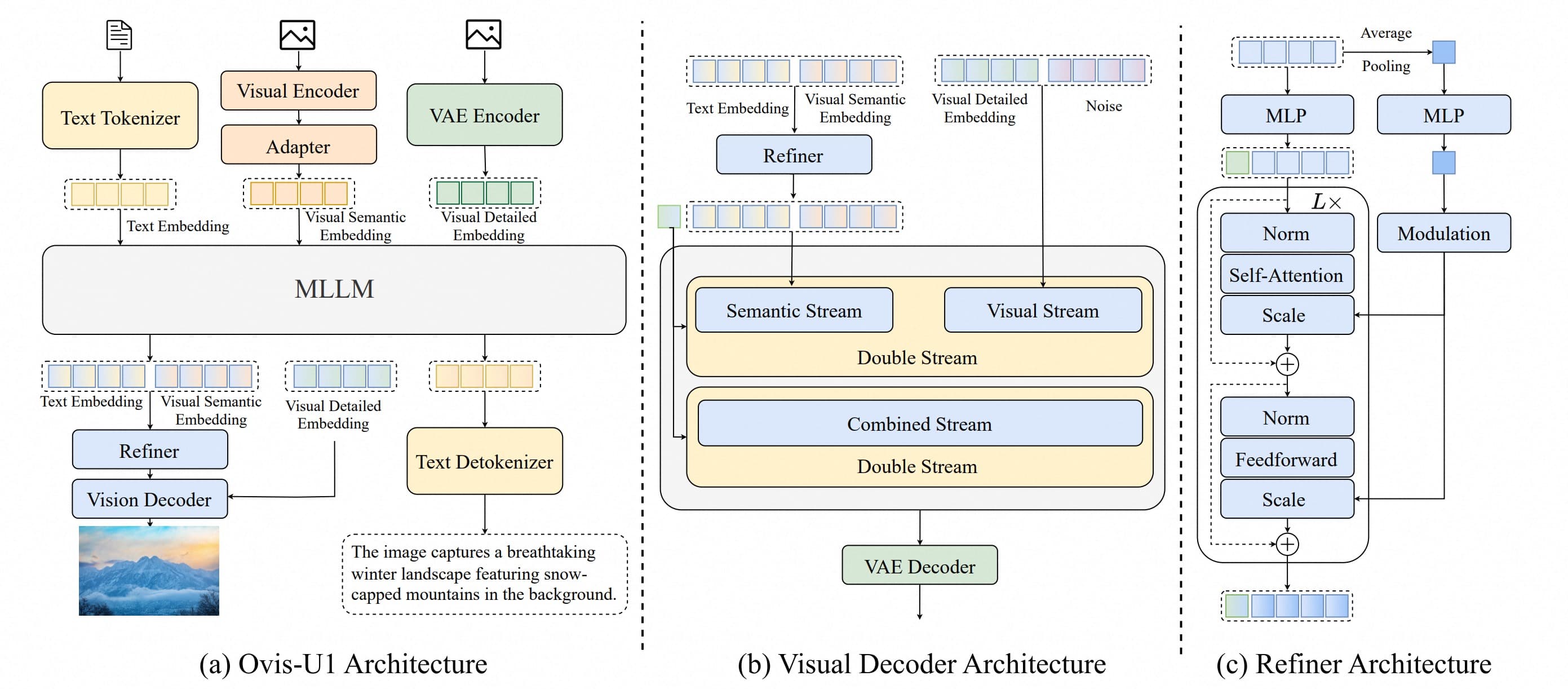
The field of open-source multimodal AI has a flexible new entry with the release of Ovis-U1-3B, a 3-billion-parameter model from research group AIDC-AI. Released under a permissive Apache 2.0 license, Ovis aims to bridge the gap between models that understand images and those that create them.
Unlike specialized models that handle either vision-language tasks or text-to-image generation, Ovis-U1-3B is designed as a unified, "any-to-any" system. This means it can accept various combinations of text and images as input to produce either text or images as output. The model's capabilities include standard tasks like visual question answering and image captioning, but also extend to text-to-image generation and instruction-based image editing within the same architecture.
According to the project's release notes, Ovis is built upon a pre-trained language model and a stable diffusion model, using a shared interface to manage its diverse set of tasks. This integrated approach allows it to handle complex instructions that might involve both analyzing and modifying an image in a single turn.
The significance of Ovis lies in its versatility at a relatively compact size. By combining traditionally separate capabilities, the model provides a foundation for more integrated and conversational AI assistants. For developers, this could simplify the toolchain required for building applications that need to both see and create. The model and its weights are available now on Hugging Face.
Sources
- Visit
AIDC-AI/Ovis-U1-3B
Hugging Face
More in Any-to-Any

Thinking Machines Debuts Inkling Small, a Compact Multimodal MoE
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.

KRAFTON releases A.X-K2 Raon speech MoE model
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.

Microsoft's Mage-VL Streams Video Natively
A codec-native multimodal foundation model aims to understand live video and vision-language input in real time.
0 comments
No comments yet. Be the first to weigh in.