Thinkingmachines/Vision-Language
Thinking Machines Debuts Inkling Small, a Compact Multimodal MoE
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.
Category · vision
Open vision-language models that read images alongside text — for document understanding, screenshots, charts, and visual question answering you can run yourself.
74 releases
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.
A codec-native multimodal foundation model aims to understand live video and vision-language input in real time.
Switzerland's open-model effort ships a 70-billion-parameter, multilingual and multimodal system that anyone can use, modify, and deploy.
A 27B-parameter vision-language model built to drive browsers and desktop apps like a human operator.
A fully open multimodal model aims to reason jointly across audio, images, and long-form video.
The Intern-S2 preview arrives as a very large multimodal system under a permissive Apache-2.0 license.
The lab's inaugural open-weights release is a mixture-of-experts system that takes image and audio inputs, shipped under a permissive Apache 2.0 license.
The Chinese research group's new vision-language model targets streaming understanding of video and images rather than static frames.
A compact 0.8B vision-language model aims to parse full documents—text, tables, and formulas—in a single pass.
The new open-weights family adds a mixture-of-experts design, encoder-free multimodal inputs, and an optional thinking mode.
The 4-billion-parameter vision-language model targets on-screen and mobile automation, built atop Qwen3-VL.
A single 7B model from SenseTime folds vision-language understanding, image generation, editing, and perception into one system.
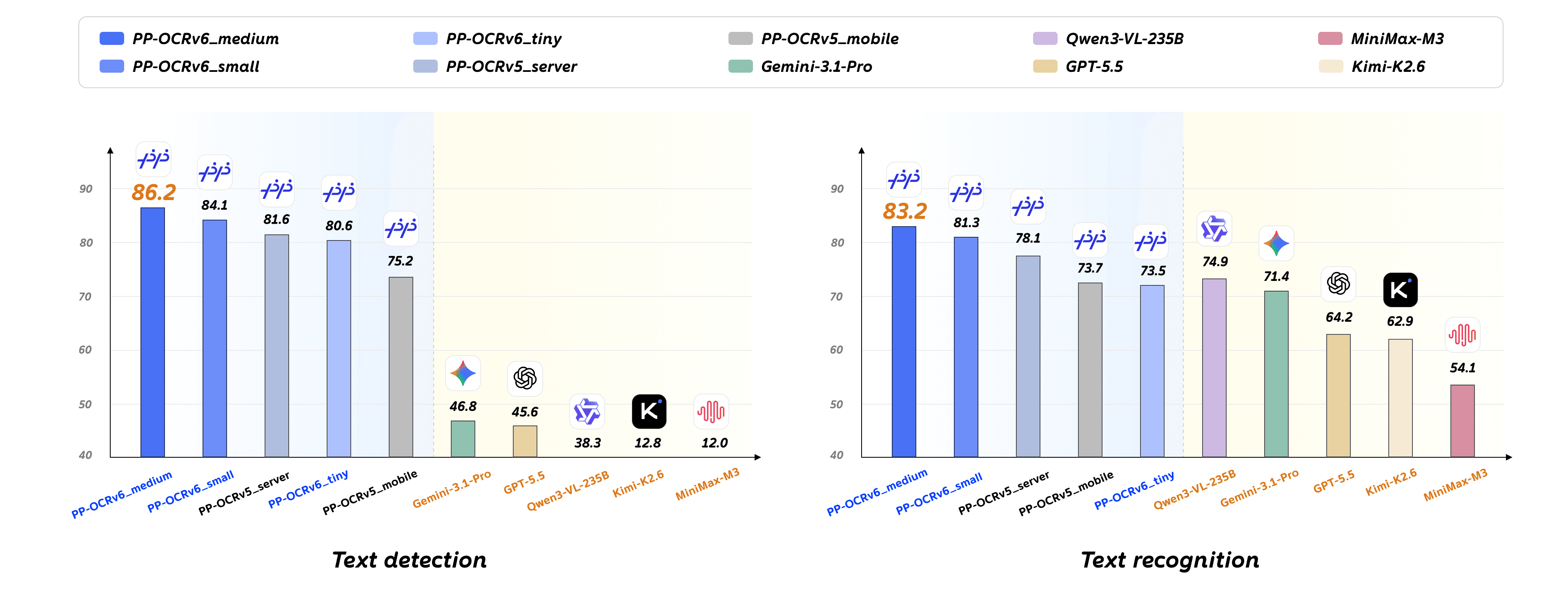
The latest release of PaddlePaddle's optical character recognition suite spans models from 1.5M to 34.5M parameters under an Apache 2.0 license.
Datalab's new open vision-language model targets structured data extraction from documents, turning messy PDFs into clean JSON.
The Chinese tech giant's multilingual vision-language model targets text extraction across languages and document types.
The open-weights multimodal model leans into coding and agentic tasks, extending Moonshot's Kimi line into a new scale bracket.
The new Mixture-of-Experts model from the Chinese AI company can generate code while also understanding visual inputs, a rare combination in open models.
The new 26B parameter model from DeepMind uses a diffusion-based architecture, a technique more common in image generation, to produce text.
Baidu's open-source OCR toolkit ships an Apache-licensed text-line detector in safetensors format, tuned for a balance of accuracy and speed.
The new open-weight model from MiniMax AI combines vision, coding, and reasoning using a Mixture-of-Experts architecture.
The new 12-billion-parameter open model from DeepMind introduces a unified 'any-to-any' architecture for advanced multimodal tasks.
The new 12-billion-parameter model from Google DeepMind is designed to handle a flexible mix of data types, moving beyond traditional text and image inputs.
The new 30-billion parameter Mixture-of-Experts model handles text and images while using only 3 billion active parameters for inference.
The new 26-billion-parameter model from DeepMind uses a mixture-of-experts design for greater efficiency and is tuned for assistant-style tasks.
The new 31-billion-parameter model is an instruction-tuned, 'any-to-any' powerhouse released under a permissive Apache 2.0 license.
The new dense model, licensed under Apache 2.0, brings both text and image understanding to the midrange parameter space.
The new Qwen3.6-35B-A3B from Alibaba's Qwen team combines vision and language capabilities using an efficient sparse architecture.
The Chinese AI lab has published weights for its new vision-language model, though a restrictive license limits its use to research applications.
The new open-source vision-language model is designed for high-resolution image understanding on mobile and edge devices.
The new HY-Embodied 0.5 is a vision-language model designed specifically for multi-object tracking in dynamic, real-world environments.
The new vision-language model from the Chinese tech giant is designed for complex, multilingual optical character recognition and layout analysis.
The new open-source model from DeepMind uses a Mixture-of-Experts architecture to handle both text and image inputs efficiently.
The new 31-billion-parameter model is instruction-tuned and can process both text and images, marking a significant expansion for the Gemma family.
The new 3-billion-parameter model, based on the company's Eagle architecture, is designed for high-precision visual grounding tasks.
The new 2-billion-parameter model from Google DeepMind brings efficient image-and-text understanding to the open-source Gemma family.
The new 2-billion-parameter model from DeepMind can process text, vision, and audio, making it a versatile and efficient foundation for developers.
The new 4-billion-parameter vision-language model brings image and text understanding to Google's popular open-source family.
The new 4-billion parameter model from Google DeepMind is designed for versatile input and output, handling text, images, and other data types.
The new 800-million-parameter model is the smallest in the Qwen3.5 family, designed for efficient multimodal tasks on consumer-grade hardware.
The new Qwen3.5-4B model combines text and image understanding in a compact, permissively licensed package for developers.
The new open-source vision-language model from Alibaba's Qwen team offers strong performance in a compact, Apache 2.0-licensed package.
The new Qwen3.5-122B-A10B combines a massive parameter count with an efficient Mixture-of-Experts architecture for advanced vision and language tasks.
The new model from Alibaba's Qwen team combines multimodal understanding with a 131K token context window under a permissive Apache 2.0 license.
The new Qwen3.5-35B-A3B model from Alibaba combines vision and language capabilities with a resource-friendly Mixture of Experts design.
The new open-source model from Alibaba uses a Mixture-of-Experts architecture to balance massive scale with efficient inference.
The new MiniCPM-o 4.5 model from the open-source research group can process and generate interleaved combinations of images, text, and audio.
The new model from OpenBMB supports mixed-modality inputs and outputs, from text and images to audio and video, in a single efficient package.
The new vision-language model from the creators of the GLM series is specialized for recognizing and extracting text from images across multiple languages.
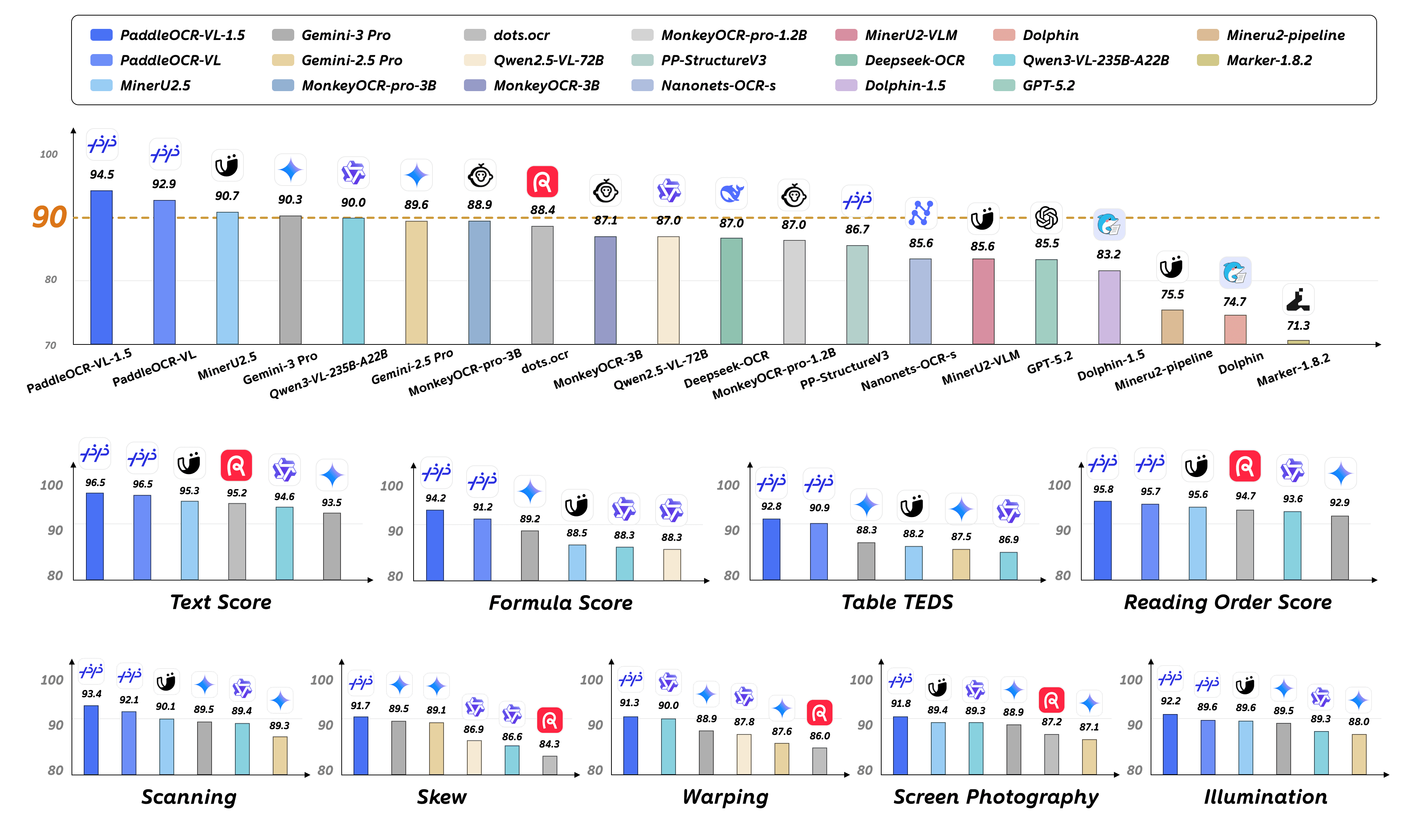
The new PaddleOCR-VL model is built to parse not just text, but also the tables, formulas, and page layouts found in complex documents.
The new open vision-language model is designed to extract text and understand structure from complex, multilingual documents.
The new vision model from the Paris-based AI lab uses Mistral architecture to extract text and structure from complex documents like PDFs and forms.
The new 4-billion-parameter vision-language model is specialized for tasks in radiology, pathology, and complex clinical reasoning.
The new vision-language model from the Chinese AI firm uses a Mixture-of-Experts architecture and is now available on Hugging Face.
The new model from the GLM-4.6V family offers a fast, MIT-licensed option for developers working with both text and images.
The new vision-language model from Tencent Hunyuan offers a compact, end-to-end solution for optical character recognition.
The latest Segment Anything Model extends Meta's mask-generation lineage from still images into video, now available on Hugging Face.
The new ERNIE 4.5 VL model brings advanced multimodal reasoning to the open-source community with an efficient Mixture-of-Experts architecture.
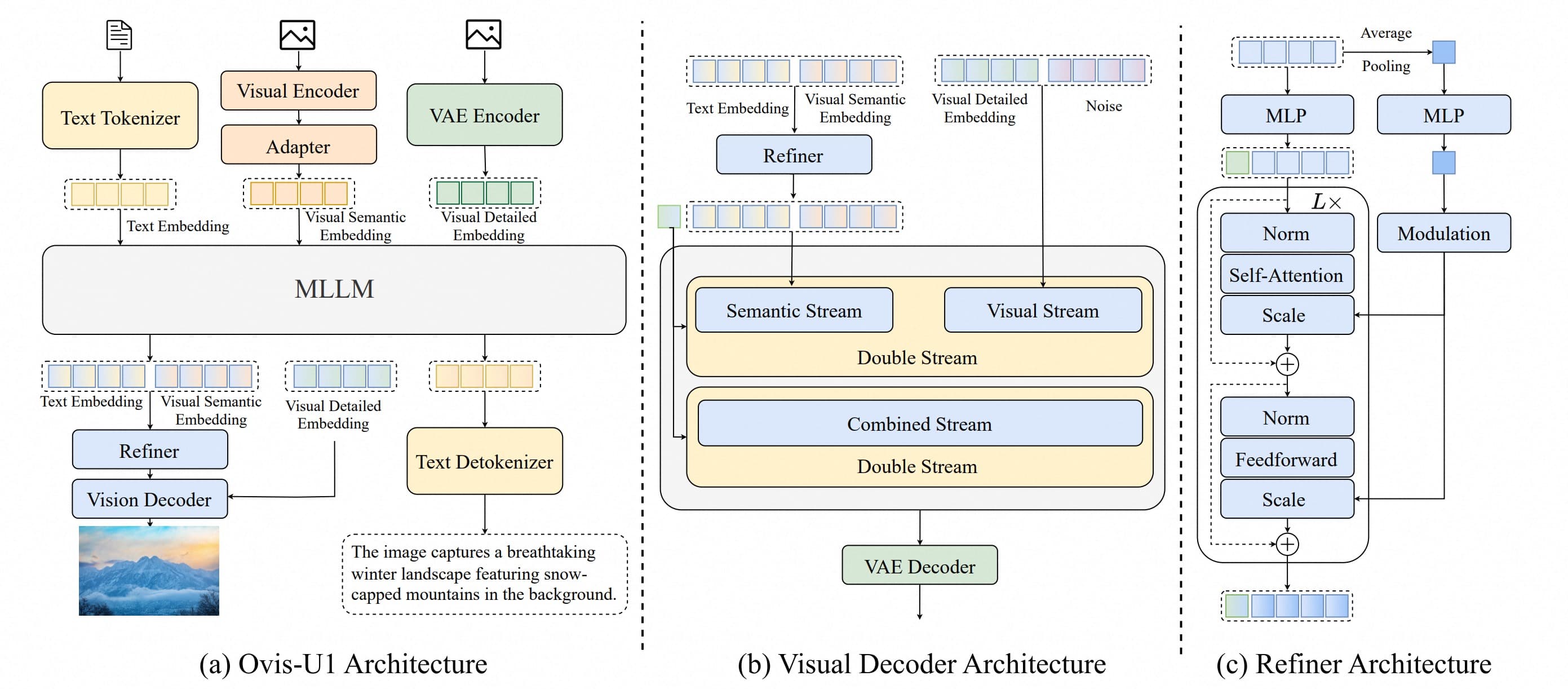
The new open-source model from the Allen Institute for AI unifies text and image understanding and generation into a single architecture.
The 7-billion-parameter model is designed to understand and interact with graphical user interfaces, building on Alibaba's open-source Qwen2.5-VL.
The new vision-language model from Datalab is fine-tuned from Qwen2-VL to specialize in extracting text and structure from complex documents.
The new vision-language model uses a novel context compression technique to efficiently extract text and structure from complex documents.
The new vision-language model is fine-tuned to understand not just text, but the complex structure of tables, charts, and formulas.
The latest vision-language model from the popular Qwen series is instruction-tuned and available under an Apache 2.0 license.
The new 16-billion-parameter model uses a sparse Mixture-of-Experts design to efficiently handle 'any-to-any' data combinations, from text to images.
The new open-source model from Alibaba uses a Mixture-of-Experts architecture to make its powerful vision-language capabilities more efficient to run.
The new 30B Mixture-of-Experts model from Alibaba's Qwen team can process and generate content across text, image, and audio formats.
The new 30-billion-parameter Mixture-of-Experts model from Alibaba's Qwen team is designed to show its reasoning process for complex multimodal tasks.
The new Mixture-of-Experts model from Alibaba is fine-tuned to generate detailed, multilingual descriptions for complex audio content.
The next generation of the efficient, open-source vision-language model is now available for early testing and feedback.
The new vision-language model from the open-source research group demonstrates strong OCR and video understanding capabilities in a small package.
The new Mixture-of-Experts model offers strong multimodal reasoning capabilities under a permissive MIT license.
The new 3B-parameter model from rednote-hilab uses a vision-language approach to parse tables, layouts, and even mathematical formulas.
The new GLM-4.1V-9B-Thinking model makes its vision and chain-of-thought reasoning capabilities available under a permissive MIT license.
The new 3-billion-parameter model from AIDC-AI combines vision-language understanding and image generation into a single 'any-to-any' framework.