Meituan/Text / LLM
Meituan Ships a Lighter, Sparser LongCat-Flash
The food-delivery giant's newest open model trims its mixture-of-experts design for more efficient inference under an MIT license.
Category · text
Open-weight large language models for chat, writing, and general reasoning — the foundation models you can download, fine-tune, and self-host instead of calling a closed API.
103 releases
The food-delivery giant's newest open model trims its mixture-of-experts design for more efficient inference under an MIT license.
The MIT-licensed mixture-of-experts model returns in an updated build shipping with FP8 weights for cheaper inference.
The latest checkpoint in DeepSeek's V4 line leans into agentic workflows while keeping the permissive MIT license.
The new mixture-of-experts model activates 37B parameters per token and targets English, Korean, and Spanish reasoning tasks.
The Korean telecom carrier's latest open language model targets English, Korean, Chinese, Japanese, and Spanish under a permissive license.
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.
Switzerland's open-model effort ships a 70-billion-parameter, multilingual and multimodal system that anyone can use, modify, and deploy.
A new open mixture-of-experts model with 16B total parameters and just 3B active is tuned to run on AMD's own accelerator stack.
Kuaishou's coding team ships an open mixture-of-experts model built on the Qwen3.5 MoE architecture and tuned for agentic development work.
The Korean AI firm's latest open release scales to 250 billion parameters with a mixture-of-experts design tuned for English and Korean.
The Korean AI lab's preview release is a mixture-of-experts language model built for long-context, multilingual work.
A collaborative European effort ships a dense 30-billion-parameter model that claims top marks on both English and German benchmarks.
A new Apache-2.0 mixture-of-experts model that generates text through diffusion rather than left-to-right decoding.
The lab's inaugural open-weights release is a mixture-of-experts system that takes image and audio inputs, shipped under a permissive Apache 2.0 license.
A new mixture-of-experts model learns to reason through reinforcement learning alone, without human-annotated chains of thought.
The AI coding startup puts a version of its Laguna family on Hugging Face under the permissive OpenMDW license.
The multilingual instruct model activates 28B parameters per token and leans on hybrid attention for efficiency at scale.
A ternary-weight 27B model with hybrid attention aims to run large-model reasoning on everyday hardware.
The company's latest mixture-of-experts model arrives as an openly licensed conversational LLM on Hugging Face.
The new open-weights family adds a mixture-of-experts design, encoder-free multimodal inputs, and an optional thinking mode.
The new Apache-2.0 mixture-of-experts model activates just 6B parameters per token, trading raw density for cheaper inference.
A Mamba-2 mixture-of-experts model claims top marks in both English and German benchmarks.
A 230-million-parameter language model built to run locally on constrained hardware like the Raspberry Pi.
A 230-million-parameter model built to run on constrained hardware like Raspberry Pi and edge robotics.
A 230-million-parameter language model built to run on hardware as modest as a Raspberry Pi.
The Chinese delivery giant continues its push into open AI with a new text model on Hugging Face.
The new flagship arrives as a mixture-of-experts system with FP8 weights and open reasoning capabilities under a permissive license.
A lighter, faster member of DeepSeek's V4 line arrives on Hugging Face under a permissive MIT license.
The new dense model ships in GGUF format under a permissive MIT license, aimed at local and self-hosted deployment.
A 230-million-parameter multilingual model built to run efficiently at the edge rather than in the cloud.
A 75-billion-parameter mixture-of-experts reasoning model that activates just 9 billion parameters per token.
The 75B-parameter model activates just 9B per token and ships in NVIDIA's NVFP4 format for efficient inference.
The flagship of a new open model family arrives under a permissive MIT license, with reasoning among its stated strengths.
Alibaba's new MoE model acts as a language world model, generating the environments that agents act within.
InclusionAI's new mixture-of-experts model bets that agent-horizon scaling can rival far larger systems on long-running tasks.
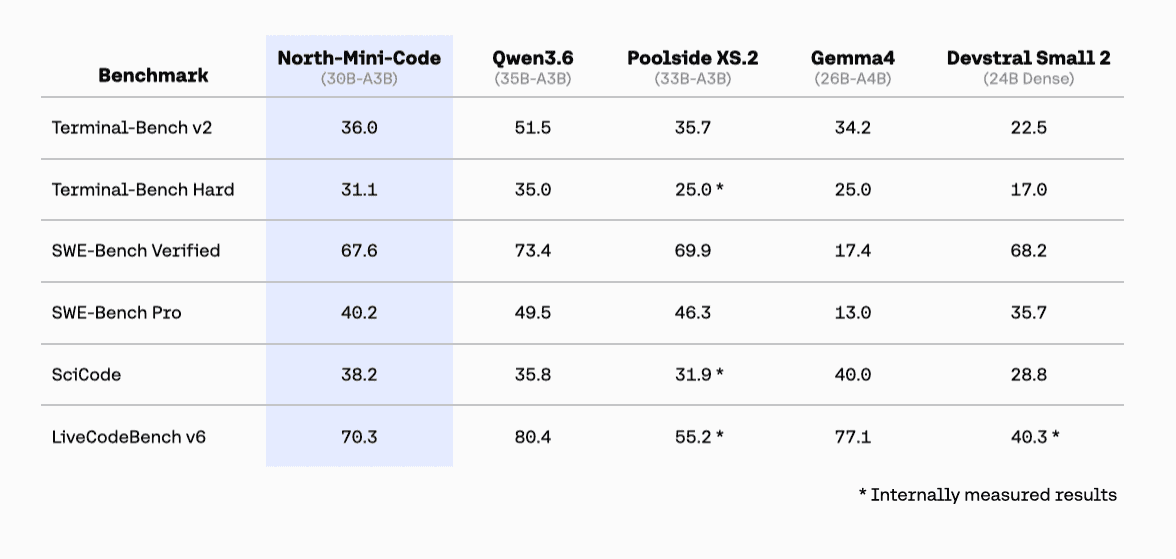
A compact, MIT-licensed 9B model built for autonomous coding tasks arrives on Hugging Face.
An MIT-licensed mixture-of-experts model targets self-scaffolding code tasks without the footprint of a frontier system.
The compact, code-focused language model arrives on Hugging Face under an open model license.
The new bilingual model from the Chinese AI firm uses a Mixture of Experts architecture and sparse attention under a fully permissive license.
The AI coding startup steps into open weights with an Apache-2.0 mixture-of-experts model built for text and code.
A compact Qwen3-derived model built to explore repositories, released under a permissive MIT license.
The open-weights multimodal model leans into coding and agentic tasks, extending Moonshot's Kimi line into a new scale bracket.
The new 3-billion-parameter model from the Chinese tech giant focuses on challenging benchmarks in mathematics, coding, and graduate-level questions.
The new Mixture-of-Experts model from the Chinese AI company can generate code while also understanding visual inputs, a rare combination in open models.
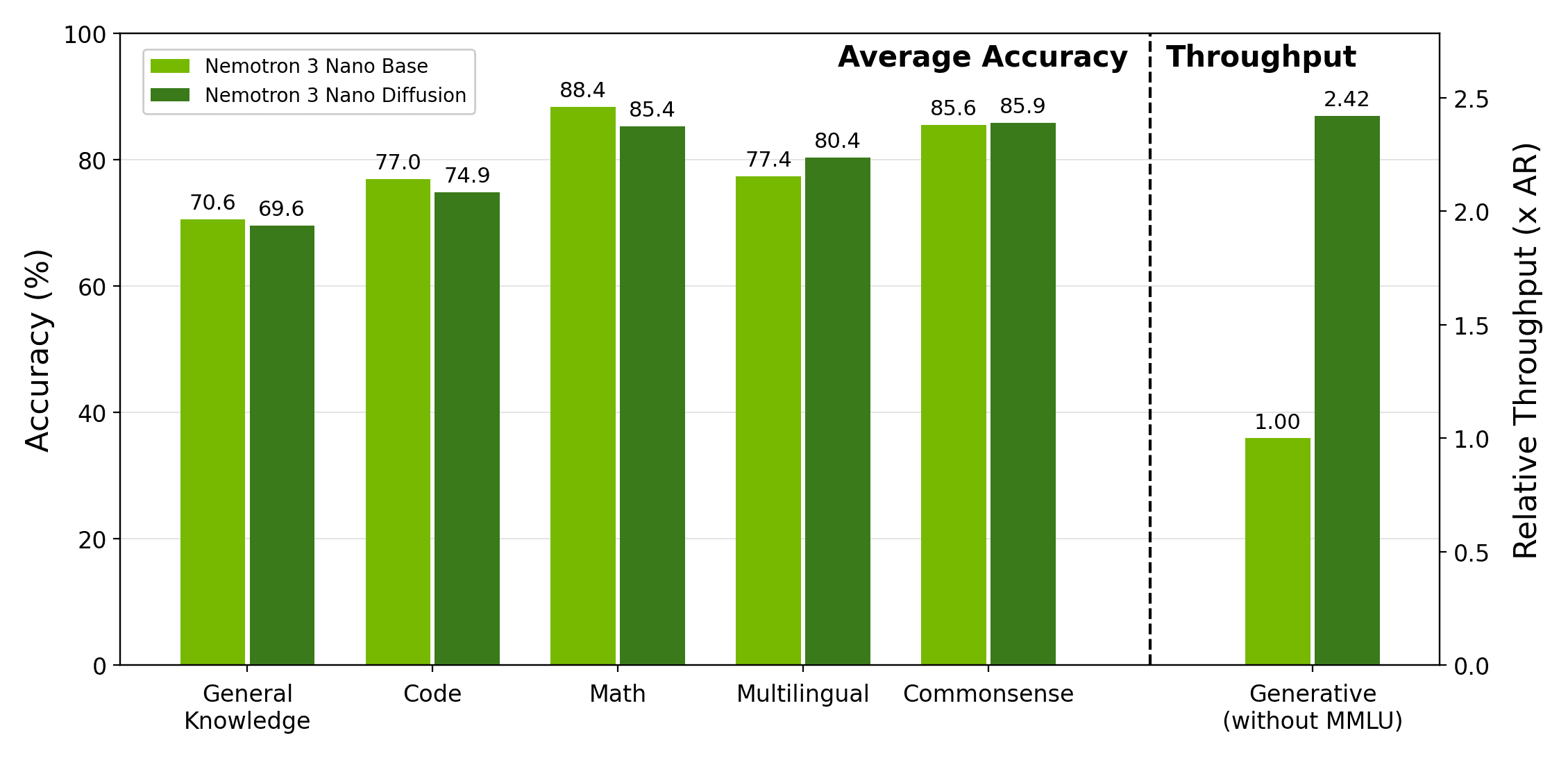
The new 26B parameter model from DeepMind uses a diffusion-based architecture, a technique more common in image generation, to produce text.
The new Apache 2.0-licensed model is designed for code generation and agentic chat applications, using a Mixture-of-Experts architecture for efficiency.
The new 12-billion-parameter open model from DeepMind introduces a unified 'any-to-any' architecture for advanced multimodal tasks.
The new 12-billion-parameter model from Google DeepMind is designed to handle a flexible mix of data types, moving beyond traditional text and image inputs.
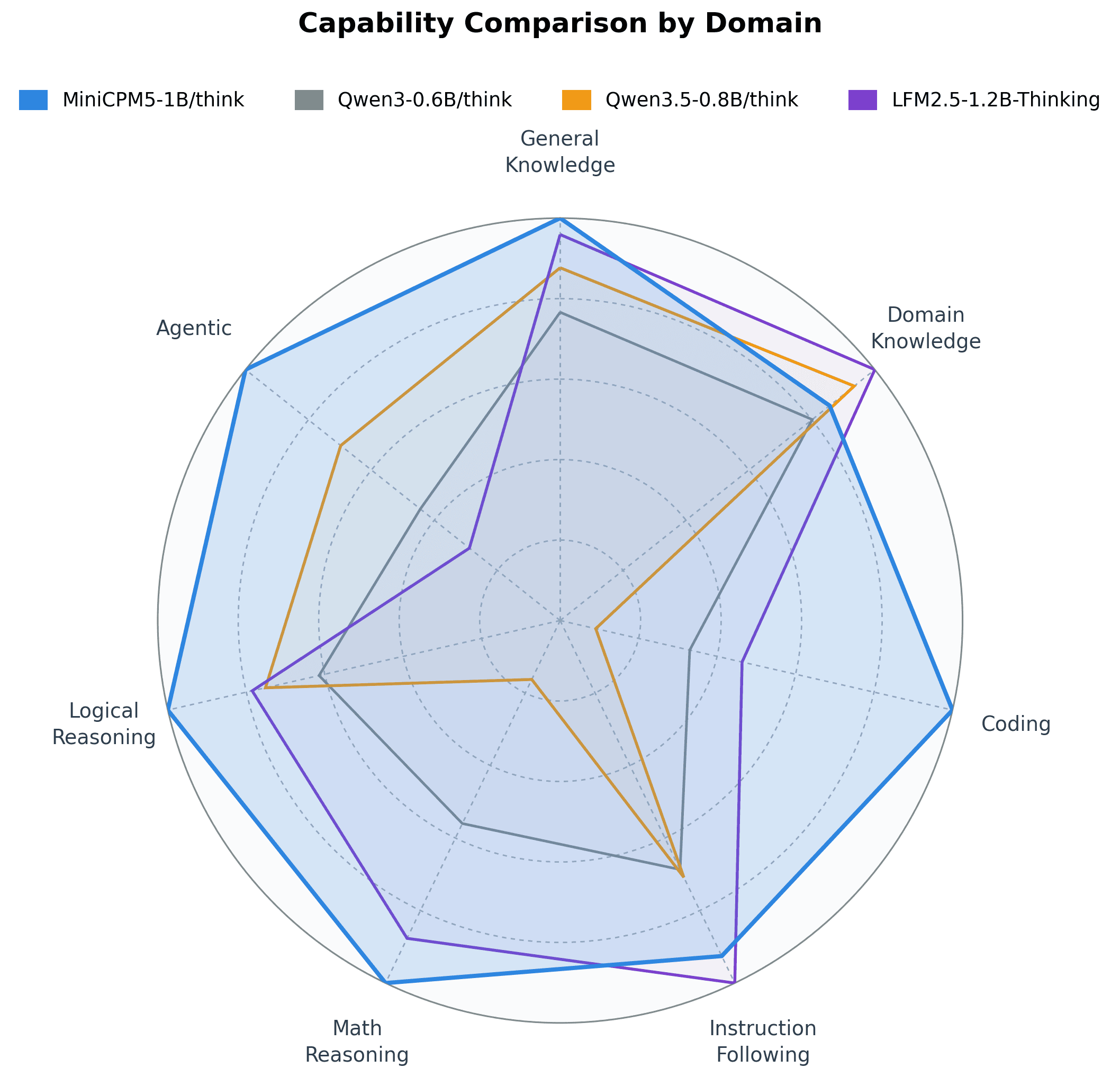
The compact 1B-parameter model brings long-context handling and tool-calling to phones and laptops.
The team behind GLiNER releases an open-source small language model aimed at making safety moderation cheaper and quicker to run.
Cactus Compute distilled Gemini's tool-calling behavior into a tiny model meant to run locally.
The 1.8 billion-parameter model from the Chinese tech giant is designed for high-quality translation across a wide range of language pairs.
Moonshot AI's open-weights mixture-of-experts model reportedly outperformed Claude, GPT-5.5, and Gemini on a programming challenge.
The new 26-billion-parameter model from DeepMind uses a mixture-of-experts design for greater efficiency and is tuned for assistant-style tasks.
The new 31-billion-parameter model is an instruction-tuned, 'any-to-any' powerhouse released under a permissive Apache 2.0 license.
The new 4-billion-parameter model is instruction-tuned for 'any-to-any' tasks, handling a flexible mix of data types.
The new compact model from DeepMind is instruction-tuned for "any-to-any" tasks, capable of processing and generating mixed data types.
The new flagship model combines a Mixture-of-Experts architecture with a permissive MIT license, positioning it for wide commercial adoption.
The new Mixture of Experts model from the Beijing-based AI lab is optimized for fast, efficient conversational AI and carries a fully permissive license.
The new dense model, licensed under Apache 2.0, brings both text and image understanding to the midrange parameter space.
The new Qwen3.6-35B-A3B from Alibaba's Qwen team combines vision and language capabilities using an efficient sparse architecture.
The Chinese AI lab has published weights for its new vision-language model, though a restrictive license limits its use to research applications.
An experimental 30B mixture-of-experts base model blends diffusion and Mamba ideas under a two-tower design.
A new 30B mixture-of-experts base model activates just 3B parameters per token and pairs a hybrid diffusion/Mamba design.
The new conversational language model from the Chinese AI company uses a Mixture-of-Experts architecture and 8-bit weights, but is released under a restrictive custom license.
The new bilingual model from the Chinese AI firm features an efficient Mixture-of-Experts architecture and a fully permissive MIT license.
The Chinese tech company has released the weights for a unified model that can process and generate combinations of text, images, audio, and video.
Cactus Compute's tiny encoder-decoder is distilled specifically for function calling at the edge, trading general chat for a narrow, useful job.
The new open-source model from DeepMind uses a Mixture-of-Experts architecture to handle both text and image inputs efficiently.
The new 31-billion-parameter model is instruction-tuned and can process both text and images, marking a significant expansion for the Gemma family.
The new 2-billion-parameter model from Google DeepMind brings efficient image-and-text understanding to the open-source Gemma family.
The new 2-billion-parameter model from DeepMind can process text, vision, and audio, making it a versatile and efficient foundation for developers.
The new 4-billion-parameter vision-language model brings image and text understanding to Google's popular open-source family.
The new 4-billion parameter model from Google DeepMind is designed for versatile input and output, handling text, images, and other data types.
The new 800-million-parameter model is the smallest in the Qwen3.5 family, designed for efficient multimodal tasks on consumer-grade hardware.
The new Qwen3.5-4B model combines text and image understanding in a compact, permissively licensed package for developers.
The new open-source vision-language model from Alibaba's Qwen team offers strong performance in a compact, Apache 2.0-licensed package.
The new Qwen3.5-122B-A10B combines a massive parameter count with an efficient Mixture-of-Experts architecture for advanced vision and language tasks.
The new model from Alibaba's Qwen team combines multimodal understanding with a 131K token context window under a permissive Apache 2.0 license.
The new Qwen3.5-35B-A3B model from Alibaba combines vision and language capabilities with a resource-friendly Mixture of Experts design.
The new open-source model from Alibaba uses a Mixture-of-Experts architecture to balance massive scale with efficient inference.
The Chinese AI company's first open-weight release uses an efficient FP8 data type but comes with a restrictive, non-commercial license.
The new Mixture-of-Experts model from the Chinese AI company combines an advanced architecture with a fully permissive MIT license for commercial use.
The new Llama-based model was trained from scratch on 3.5 trillion tokens of Chinese and English data to enhance its bilingual capabilities.
The new model from Alibaba's Qwen team uses a Mixture-of-Experts architecture and is released under the commercially-friendly Apache 2.0 license.
The new Mixture-of-Experts model from the Beijing-based AI company is optimized for speed and released under the permissive MIT license.
The new 4B-parameter model is an instruction-tuned variant of Gemma, designed specifically for high-quality multilingual translation tasks.
The new vision-language model from the Chinese AI firm uses a Mixture-of-Experts architecture and is now available on Hugging Face.
The new Mixture of Experts model from the Chinese AI firm uses 8-bit floating-point precision for a smaller memory footprint and faster inference.
The new Mixture-of-Experts model from DeepSeek AI combines an efficient FP8 architecture with a fully permissive license for commercial use.
The new Mixture-of-Experts model is designed for complex tasks but arrives in a custom compressed format with a restrictive license.
The Shanghai-based AI startup has released a new Mixture-of-Experts model focused on complex reasoning, coding, and agentic tasks.
The new 270-million-parameter model from Google DeepMind is fine-tuned specifically for reliable function calling and tool use.
The new Mixture-of-Experts model is available under a permissive MIT license and is optimized for complex reasoning and coding tasks.
The new Qwen3-Next model from Alibaba combines a large parameter count with an efficient MoE architecture to balance performance and computational cost.
The new DeepSeek-V3.1-Base is a massive 671-billion-parameter Mixture-of-Experts model designed for efficient, large-scale research and development.
The new ultra-compact model from DeepMind is designed for efficient performance in resource-constrained environments like mobile and web.
The new `gpt-oss-20b` is an Apache 2.0-licensed Mixture-of-Experts model designed to run efficiently on consumer-grade hardware.
The new 117-billion-parameter `gpt-oss-120b` is a Mixture-of-Experts model focused on reasoning, released under a permissive Apache 2.0 license.
The new Apache 2.0 model from Alibaba's Qwen team uses a Mixture-of-Experts architecture to deliver strong performance with only 3B active parameters.
The new flagship coding model from Alibaba's Qwen team uses a massive Mixture-of-Experts architecture and is released under a permissive Apache-2.0 license.
The new Mixture-of-Experts model combines massive scale with a fully permissive license, targeting complex reasoning and agentic applications.
The new Mixture-of-Experts model brings massive scale to the open-weights community, focusing on complex reasoning and coding tasks with a 128K context window.