PaddleOCR's PP-OCRv6 Adds a Medium Detection Model
Baidu's open-source OCR toolkit ships an Apache-licensed text-line detector in safetensors format, tuned for a balance of accuracy and speed.
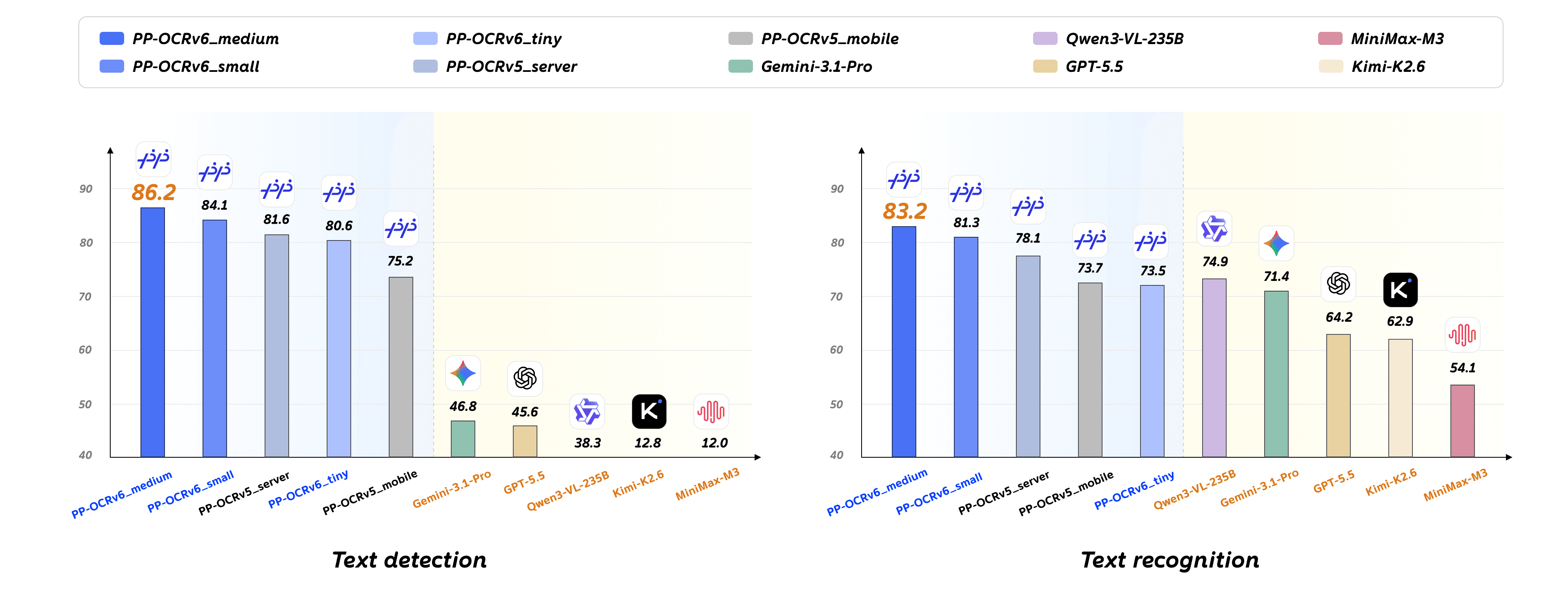
Baidu has published PP-OCRv6 Medium Detection, the text-line detection component of the latest generation of its widely used PaddleOCR toolkit. The model is available on Hugging Face in safetensors format under a permissive Apache-2.0 license.
Text detection is the first stage in most OCR pipelines: before any characters can be read, a model has to locate where text actually sits on the page. This "medium" variant targets the practical middle ground between lightweight mobile-friendly detectors and heavier, higher-accuracy ones, making it a reasonable default for documents, receipts, and natural-scene imagery.
Why it matters
PaddleOCR has become one of the more popular open OCR stacks, particularly for Chinese and multilingual text, and a modular detection model lets developers swap stages without committing to the full framework.
- Apache-2.0 licensing allows commercial use and redistribution.
- The safetensors format improves loading safety and interoperability.
- A sub-1B parameter footprint keeps inference costs modest.
As an early v6-generation release, the model signals continued investment in PaddleOCR's pipeline approach rather than a single end-to-end system. Teams already building on PaddleOCR can treat it as a drop-in detection upgrade, while others may find it a useful standalone building block for document-processing workflows.
Sources
- Visit
PaddlePaddle/PP-OCRv6_medium_det_safetensors
Hugging Face
More in Vision-Language

Thinking Machines Debuts Inkling Small, a Compact Multimodal MoE
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.

Microsoft's Mage-VL Streams Video Natively
A codec-native multimodal foundation model aims to understand live video and vision-language input in real time.

Apertus v1.5 70B arrives with an Apache-2.0 license
Switzerland's open-model effort ships a 70-billion-parameter, multilingual and multimodal system that anyone can use, modify, and deploy.
0 comments
No comments yet. Be the first to weigh in.