Baidu/Vision-Language
Baidu's PP-OCRv6 packs 50-language OCR into tiny models
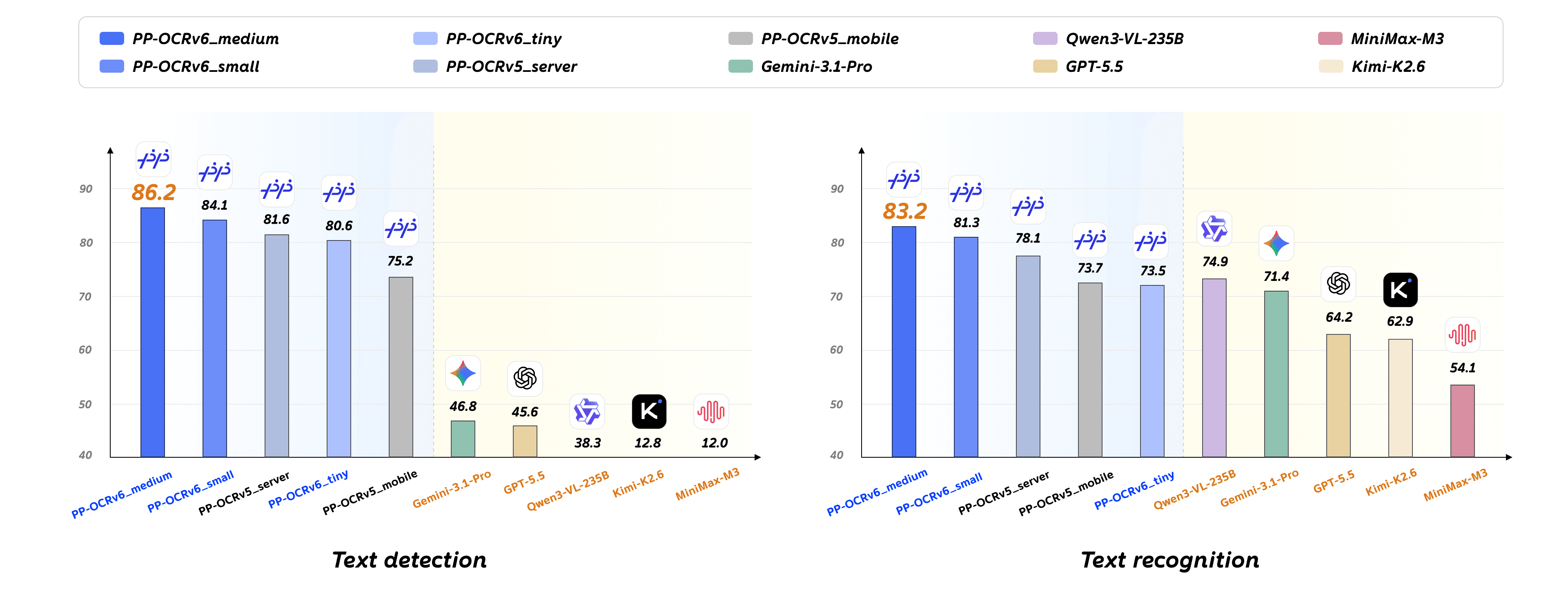
The latest release of PaddlePaddle's optical character recognition suite spans models from 1.5M to 34.5M parameters under an Apache 2.0 license.
Company
Releases
The latest release of PaddlePaddle's optical character recognition suite spans models from 1.5M to 34.5M parameters under an Apache 2.0 license.
The Chinese tech giant's multilingual vision-language model targets text extraction across languages and document types.
Baidu's open-source OCR toolkit ships an Apache-licensed text-line detector in safetensors format, tuned for a balance of accuracy and speed.
The new model from the Chinese tech giant uses a Multimodal Diffusion Transformer to generate synchronized audio and video from text or image prompts.
The large diffusion model from the Chinese tech giant is available under the commercially permissive Apache 2.0 license, a notable release for the community.
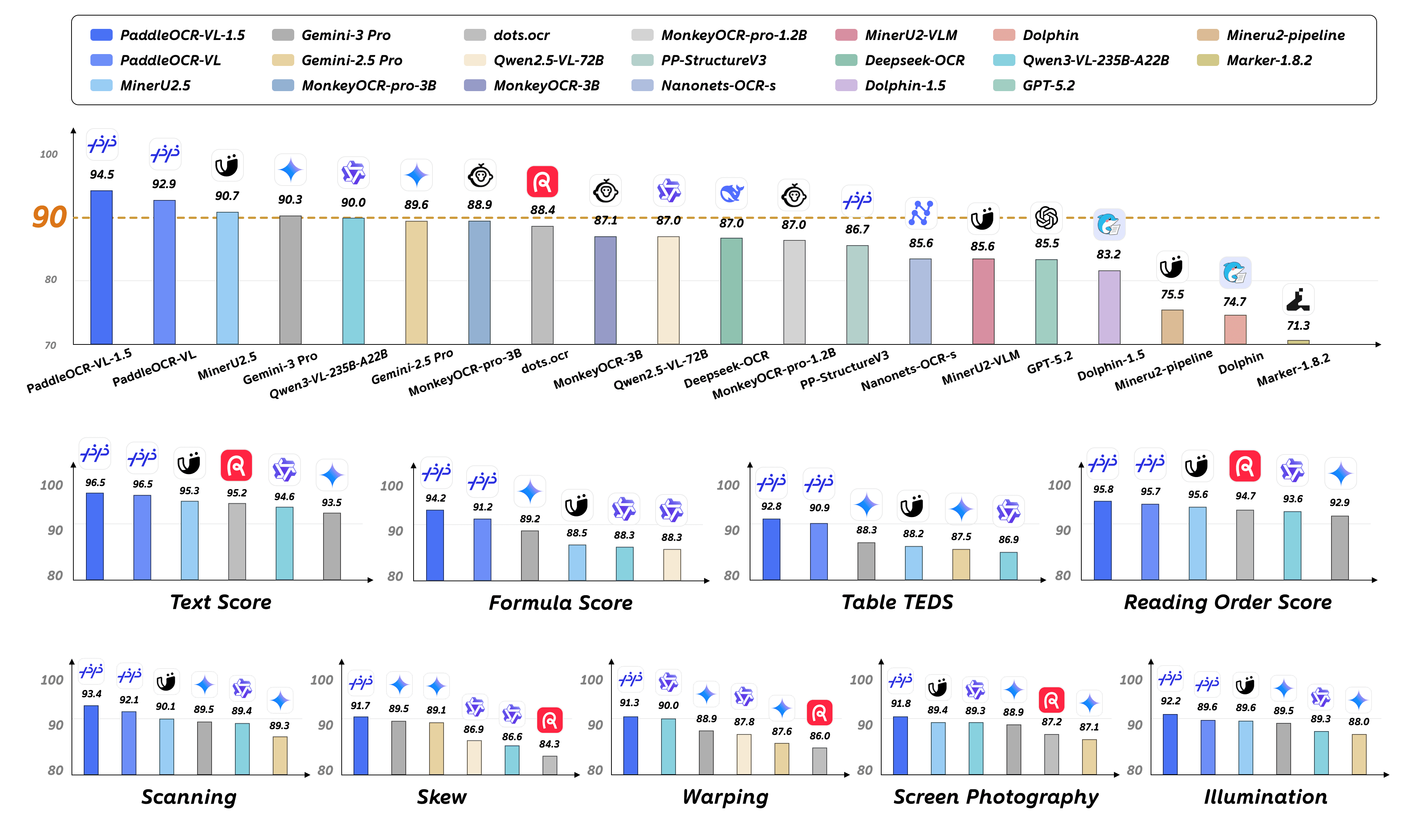
The new vision-language model from the Chinese tech giant is designed for complex, multilingual optical character recognition and layout analysis.
The new PaddleOCR-VL model is built to parse not just text, but also the tables, formulas, and page layouts found in complex documents.
The new ERNIE 4.5 VL model brings advanced multimodal reasoning to the open-source community with an efficient Mixture-of-Experts architecture.
The new vision-language model is fine-tuned to understand not just text, but the complex structure of tables, charts, and formulas.