MiniMax/Text → Video
MiniMax Releases H3 Video Model on Hugging Face
The company's new diffusion model handles text-to-video and image-to-video, with support for joint audio-video generation.
Category · video
Open text-to-video models that turn a prompt into motion — the fast-moving frontier of open-weight generative video you can self-host.
24 releases
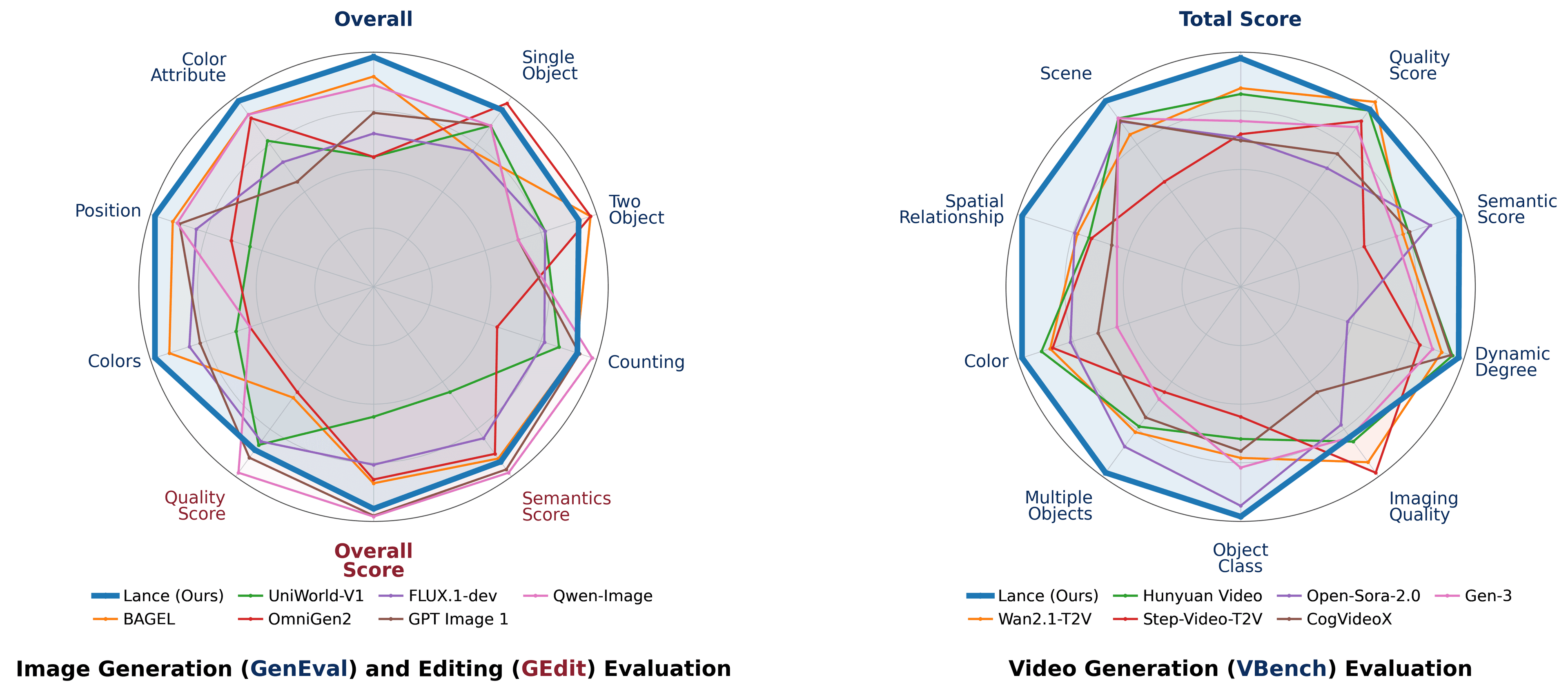
The company's new diffusion model handles text-to-video and image-to-video, with support for joint audio-video generation.
A DiT-based mixture-of-experts model activates just 3B parameters per step and ships under an Apache 2.0 license.
A new edge-optimized variant of NVIDIA's Cosmos world-model line aims to run generative video where the compute lives.
The Chinese e-commerce giant has released a new model capable of generating long-form, multi-shot videos with synchronized audio from text prompts.
The new model from the Chinese tech giant uses a Multimodal Diffusion Transformer to generate synchronized audio and video from text or image prompts.
The new model, SANA-WM, uses a bidirectional diffusion process to give creators fine-grained control over camera movement and video editing.
The 3-billion-parameter model handles image and video generation, editing, and understanding from a single set of weights under a permissive license.
The new 'Identity-Control' adapter fine-tunes the company's LTX-2.3 video model to create realistic lip-syncing for dubbing workflows.
The new Apache 2.0 licensed model uses a diffusion transformer architecture to offer a new open alternative for video generation research.
Built on their HunyuanVideo-1.5 architecture, the new model synthesizes video by combining multiple static images and text prompts into a cohesive narrative.
The new open-source model from the General Artificial Intelligence Research team can create video clips complete with audio from a variety of inputs.
The new model, based on Stable Video Diffusion, can create video and a corresponding soundtrack simultaneously from text, image, or audio prompts.
The new model generates 360p video from text or images and creates corresponding audio tracks simultaneously, a notable step for integrated audiovisual synthesis.
The new diffusion model from the creative app company can generate short video clips from text, images, audio, and even other videos.
The new diffusion model generates short video clips from text and image prompts, adding another major player to the open video space.
The Chinese tech giant has released a new MIT-licensed model capable of generating video from text, images, or by continuing existing clips.
The new open-source model combines both video generation and comprehension, a rare dual capability built on the Qwen2.5 vision-language foundation.
The new 14-billion-parameter model is a distilled, more efficient version of a larger foundation, designed for interactive video generation.
The new 14-billion-parameter model from Alibaba's PAI team offers fine-grained control over video generation using inputs like sketches and depth maps.
The new Apache 2.0-licensed generator uses a Mixture-of-Experts architecture and is available in the popular Diffusers library format for easier integration.
The new Apache 2.0 licensed model from Alibaba's team generates video from either text prompts or still images, offering a unified approach in a compact package.
The new Apache 2.0-licensed model from Alibaba's team uses a Mixture-of-Experts architecture for efficient, high-quality video generation.
The new Apache 2.0 licensed model from Alibaba's team can generate video from both text and image prompts, adding a powerful new tool to the open-source creative ecosystem.
Based on the Wan2.1 architecture, this new 14B parameter model offers fine-grained control over video generation from still images and text.