MiniMax/Text → Video
MiniMax Releases H3 Video Model on Hugging Face
The company's new diffusion model handles text-to-video and image-to-video, with support for joint audio-video generation.
Category · video
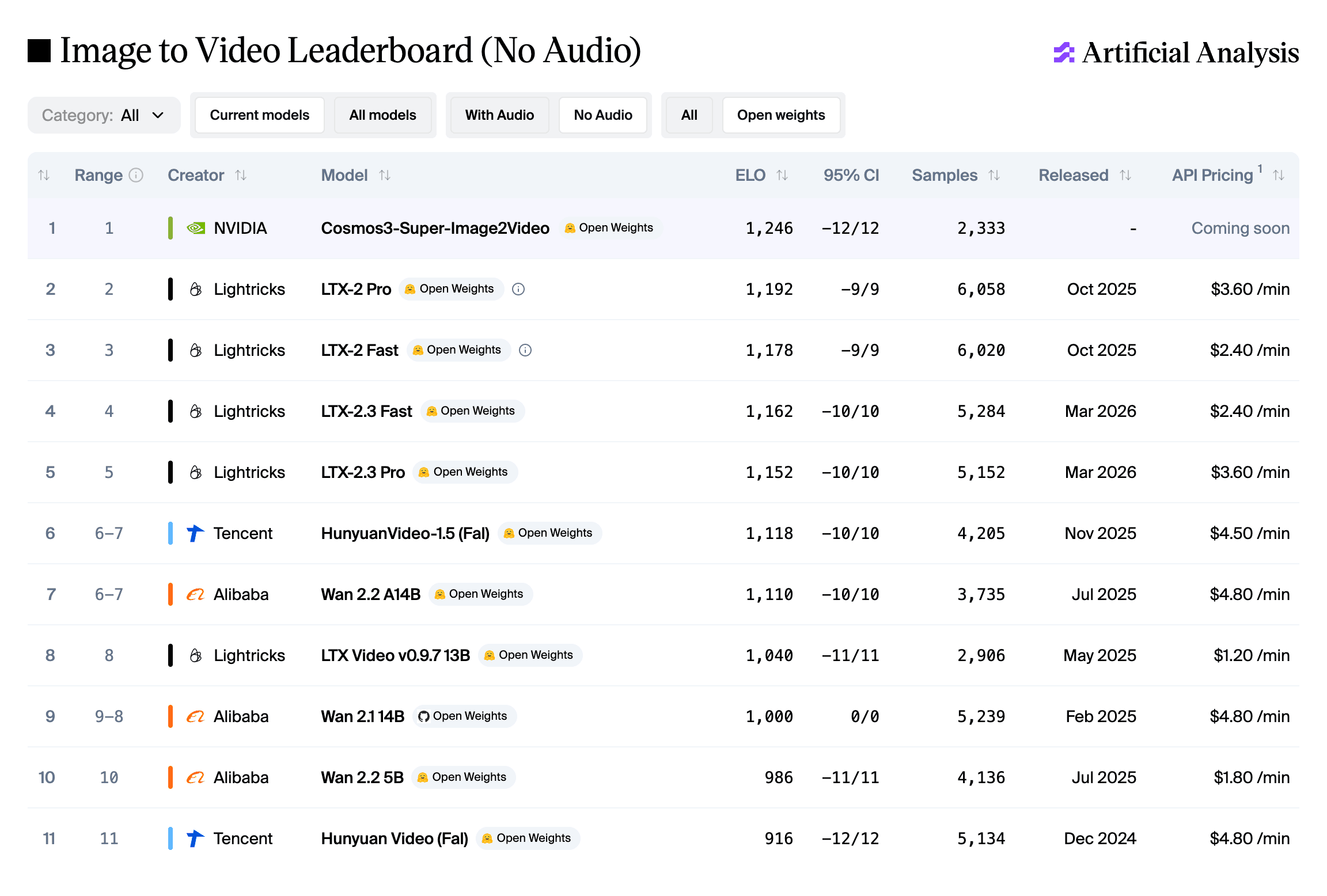
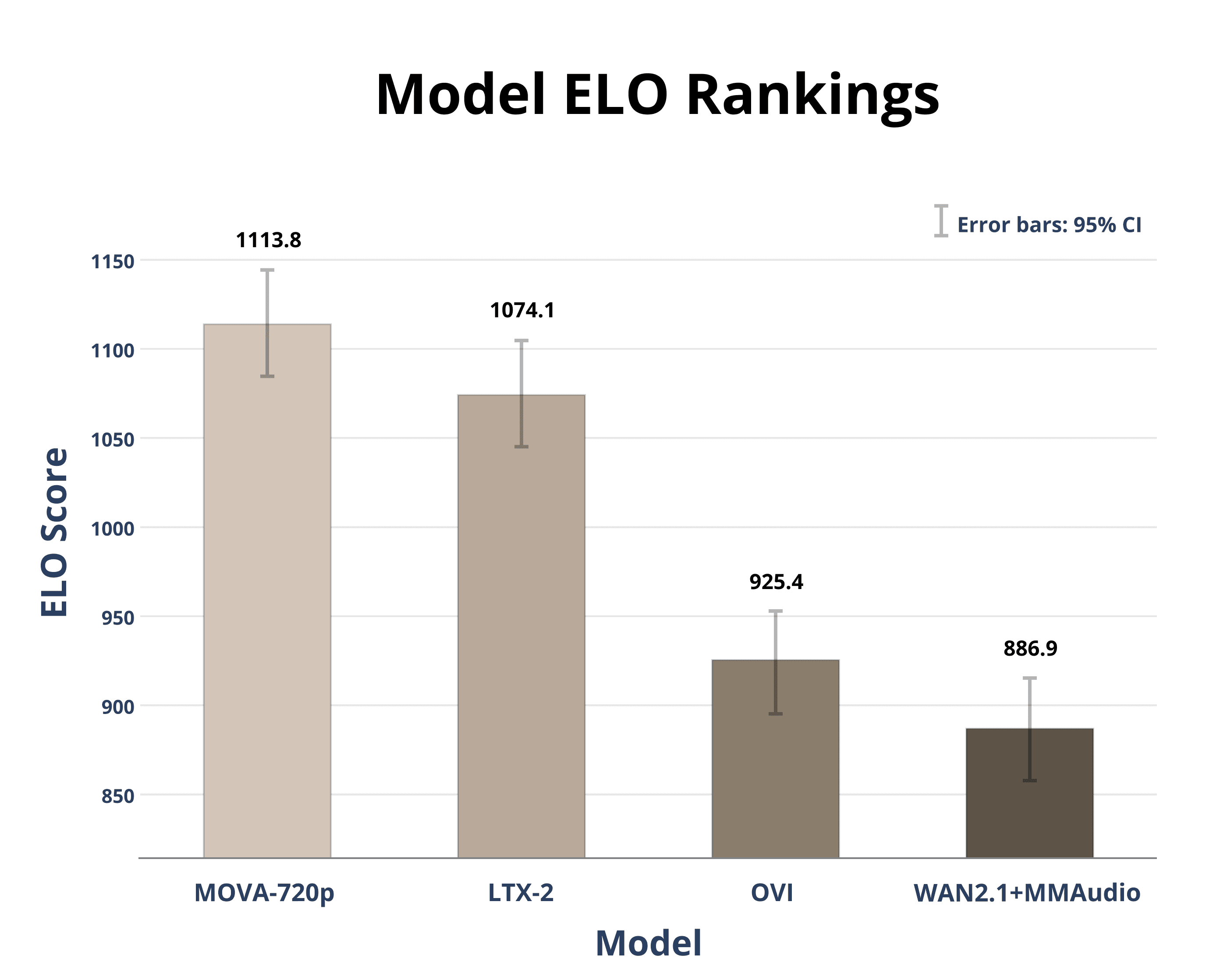
Open models that animate a still image into video — bringing photos and artwork to life with controllable motion, runnable on your own GPUs.
36 releases
The company's new diffusion model handles text-to-video and image-to-video, with support for joint audio-video generation.
Alibaba's Wan team releases an Apache-2.0 image-to-video model built for music-driven dance generation.
A new edge-optimized variant of NVIDIA's Cosmos world-model line aims to run generative video where the compute lives.
An open image-to-video world model aims to bridge physically grounded generation and robot policy learning.
The new open-source diffusion model from the company's research arm generates video clips from a single character image and a sequence of poses.
The latest release in NVIDIA's 'world model' research family aims to generate coherent and realistic video from a single static image.
An audio-driven avatar model that animates still images into talking video, with support for continuation of longer clips.
The new model, SANA-WM, uses a bidirectional diffusion process to give creators fine-grained control over camera movement and video editing.
The new 'Identity-Control' adapter fine-tunes the company's LTX-2.3 video model to create realistic lip-syncing for dubbing workflows.
The new Apache 2.0 licensed model uses a diffusion transformer architecture to offer a new open alternative for video generation research.
Built on their HunyuanVideo-1.5 architecture, the new model synthesizes video by combining multiple static images and text prompts into a cohesive narrative.
The new open-source model from the General Artificial Intelligence Research team can create video clips complete with audio from a variety of inputs.
The new model, based on Stable Video Diffusion, can create video and a corresponding soundtrack simultaneously from text, image, or audio prompts.
The new open model can generate high-definition video with synchronized audio from a flexible combination of text and image prompts.
The new model generates 360p video from text or images and creates corresponding audio tracks simultaneously, a notable step for integrated audiovisual synthesis.
The new open-source world model from researcher robbyant generates short video clips from a single image, giving users control over the virtual camera path.
The new diffusion model from the creative app company can generate short video clips from text, images, audio, and even other videos.
The new open-source model from OpenBMB uses a diffusion-based architecture to generate expressive video from a single still image.
The new model from Tencent's Hunyuan team generates dynamic video and reconstructs 3D environments using a single static picture.
The new 14-billion-parameter model uses audio input to generate realistic talking head videos from a single still image.
The new diffusion model generates short video clips from text and image prompts, adding another major player to the open video space.
The Chinese tech giant has released a new MIT-licensed model capable of generating video from text, images, or by continuing existing clips.
The new open-source model from Swiss researchers uses a novel chunking method to generate indefinitely long videos from a single still image.
Built on the Wan2.2 architecture, this new 5-billion-parameter model generates short video clips from a single image and simultaneously creates synchronized audio.
The new model from the TikTok parent company generates short video clips that maintain a person's likeness from a single reference image.
The new open-source model specializes in creating realistic videos of people, separating appearance from motion for greater control.
The new model from Tencent AI Lab generates temporally and spatially consistent video sequences from a single image, enabling virtual exploration of static scenes.
The new Wan2.2-S2V model takes a still image and a speech track to generate a realistic talking-head animation, available under a permissive license.
The new Hunyuan-GameCraft 1.0 is an open image-to-video model that generates interactive game-like scenes with precise camera control.
A new diffusion-based model from developer FrancisRing animates still images into talking avatars using only an audio track.
The new 1.3-billion-parameter model functions as an interactive 'world model,' generating controllable video scenes from a single static image.
The new open-source diffusion model from the team behind Qwen uses a Mixture-of-Experts architecture to animate still images.
The new Apache 2.0 licensed model from Alibaba's team generates video from either text prompts or still images, offering a unified approach in a compact package.
The new 14-billion parameter model from Alibaba's AI team uses a Mixture-of-Experts design and is available under the permissive Apache 2.0 license.
The new Apache 2.0 licensed model from Alibaba's team can generate video from both text and image prompts, adding a powerful new tool to the open-source creative ecosystem.
Based on the Wan2.1 architecture, this new 14B parameter model offers fine-grained control over video generation from still images and text.