OpenMOSS Releases MOVA, a 720p Multimodal Video Generator
The new open model can generate high-definition video with synchronized audio from a flexible combination of text and image prompts.
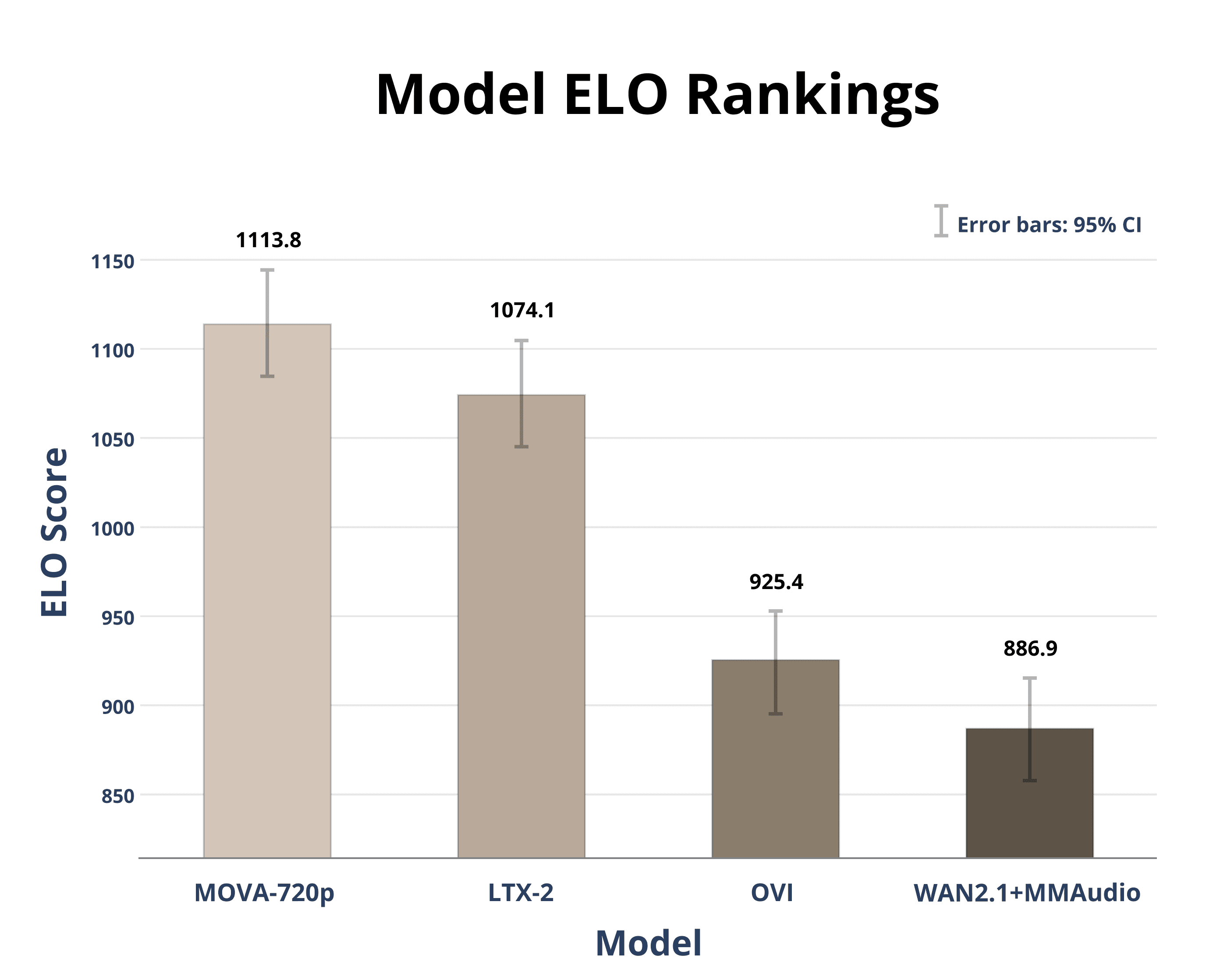
The OpenMOSS team has released MOVA 720p, a new model for generating video with synchronized audio. Unlike many generative tools that rely on a single input type, MOVA is designed for flexible, multimodal prompts, capable of creating high-definition video from text, images, or a combination of both.
This "any-to-any" architecture is the model's key feature. It allows a creator to provide an image as a starting point and then guide the animation with a text prompt, offering more direct control over the subject, action, and style of the final video. The model processes these varied inputs to produce a coherent visual sequence complete with a relevant soundtrack.
Why It Matters
Generating video at a 720p resolution (1280x720) marks a notable step for open multimodal models, which often operate at lower resolutions to manage computational demands. By integrating audio generation and supporting complex prompts, MOVA 720p pushes the capabilities of open-source video synthesis forward, narrowing the gap with proprietary systems from major tech labs.
The model and its components are available for developers to explore on the OpenMOSS team's Hugging Face repository. It is released under a custom license, so users should review the specific terms of use before integrating it into their work.
Sources
- Visit
OpenMOSS-Team/MOVA-720p
Hugging Face
More in Any-to-Any

Thinking Machines Debuts Inkling Small, a Compact Multimodal MoE
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.

KRAFTON releases A.X-K2 Raon speech MoE model
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.

Microsoft's Mage-VL Streams Video Natively
A codec-native multimodal foundation model aims to understand live video and vision-language input in real time.
0 comments
No comments yet. Be the first to weigh in.