OpenMOSS/Vision-Language
OpenMOSS Debuts MOSS-VL-Realtime for Live Video
The Chinese research group's new vision-language model targets streaming understanding of video and images rather than static frames.
Company
Releases
The Chinese research group's new vision-language model targets streaming understanding of video and images rather than static frames.
A new text-to-speech model introduces 'delay-pattern decoding' to solve common word skipping and repetition errors in parallel generation.
The open-weights team behind MOSS turns to long-form speech recognition with built-in speaker diarization and timestamps.
The new open-source model from OpenMOSS-Team generates high-quality speech in multiple languages while maintaining a remarkably small footprint.
The new system from the OpenMOSS Team uses a novel 'delay-pattern' architecture to generate natural-sounding speech in Chinese, English, and Japanese.
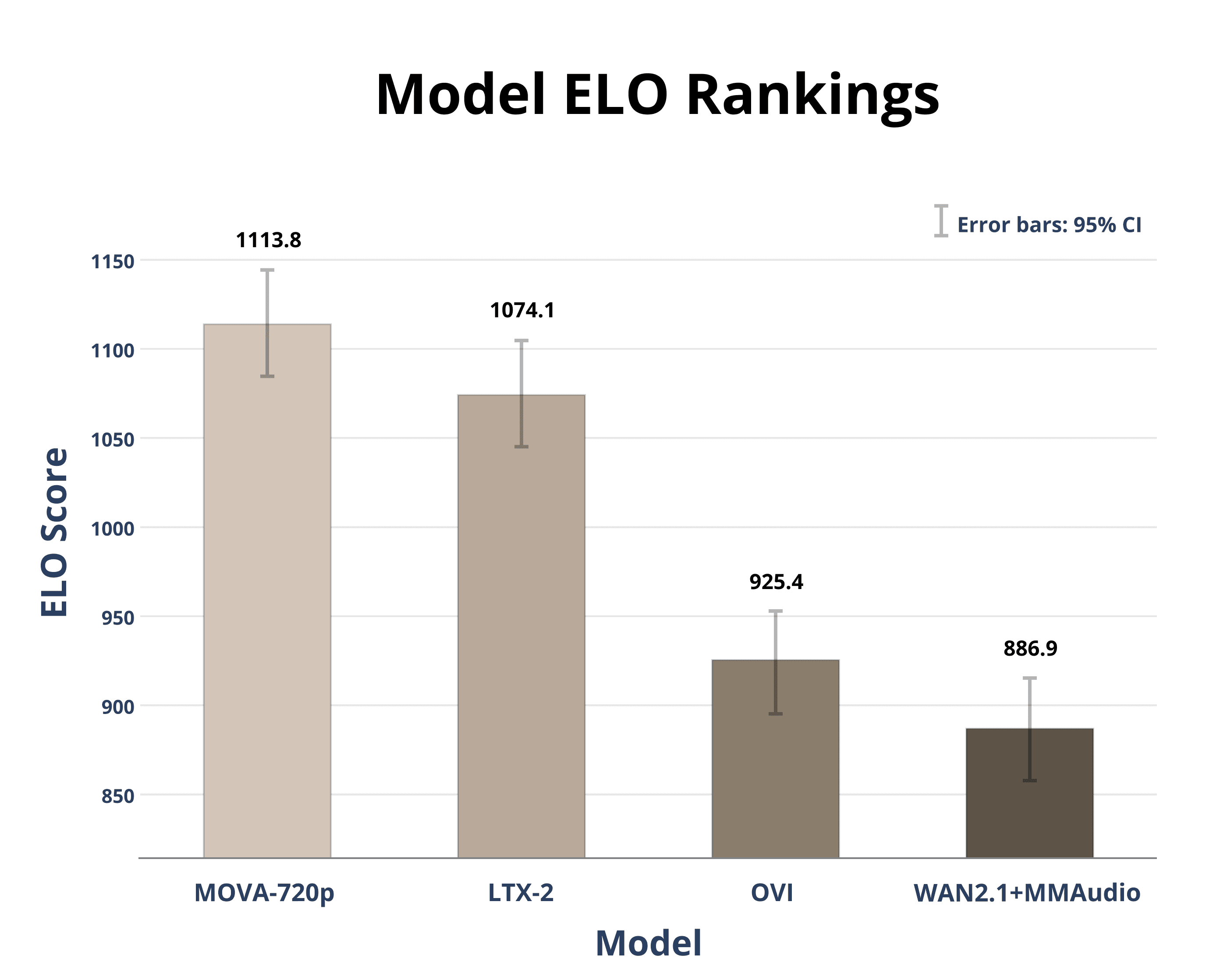
The new open model can generate high-definition video with synchronized audio from a flexible combination of text and image prompts.
The new model generates 360p video from text or images and creates corresponding audio tracks simultaneously, a notable step for integrated audiovisual synthesis.