KRAFTON/Any-to-Any
KRAFTON releases A.X-K2 Raon speech MoE model
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.
Category · audio
Open speech-recognition models that transcribe audio to text across languages — for captioning, voice interfaces, and pipelines you run on your own infrastructure.
34 releases
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.
A BitNet-quantized speech recognition model trades GPU dependence for efficient CPU inference in English and Chinese.
A Whisper-based ASR model that keeps every filler word and stamps timestamps to the individual word, now covering English and German.
An MIT-licensed speech recognition model targeting Russian, English, and Kazakh arrives on Hugging Face.
The Cohere Labs transcription model targets Arabic and English audio under a permissive open license.
Researcher Zhifei Xie has released a 1.7B-parameter model that refines Alibaba's Qwen3-ASR, showing improved performance on English and Chinese transcription benchmarks.
The open-weights team behind MOSS turns to long-form speech recognition with built-in speaker diarization and timestamps.
The 600-million-parameter model uses a FastConformer architecture for real-time, multilingual speech-to-text applications.
The new open-source model from the Chinese tech giant offers automatic speech recognition for Mandarin, Cantonese, and English under a permissive MIT license.
The new two-billion-parameter model offers transcription capabilities for at least five major languages under a permissive Apache 2.0 license.
The gaming giant behind 'PUBG' has released Raon-Speech-9B, a multimodal model for English and Korean speech recognition and synthesis.
The new automatic speech recognition model from Cohere Labs sets a new benchmark on the Hugging Face Open ASR Leaderboard for multilingual performance.
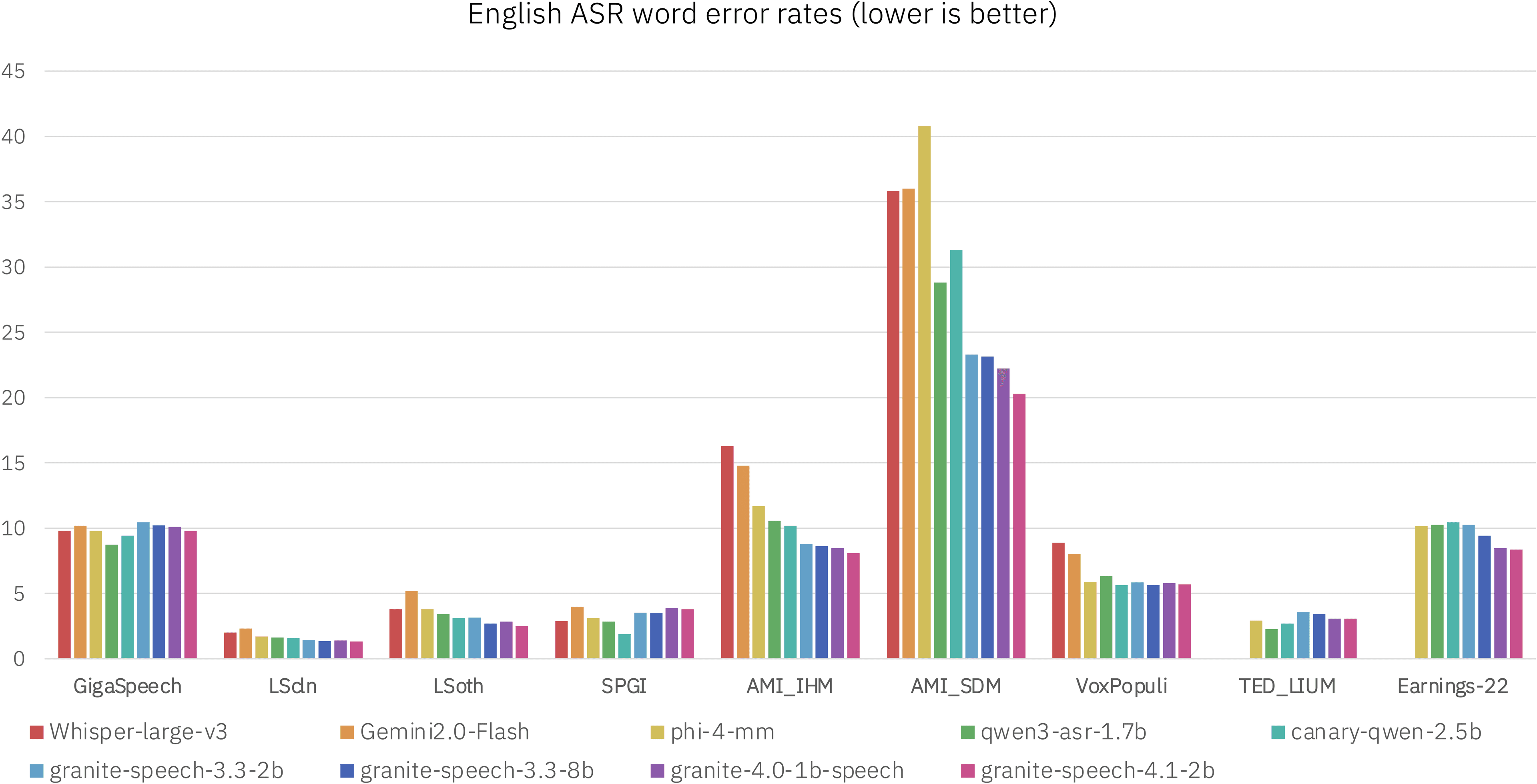
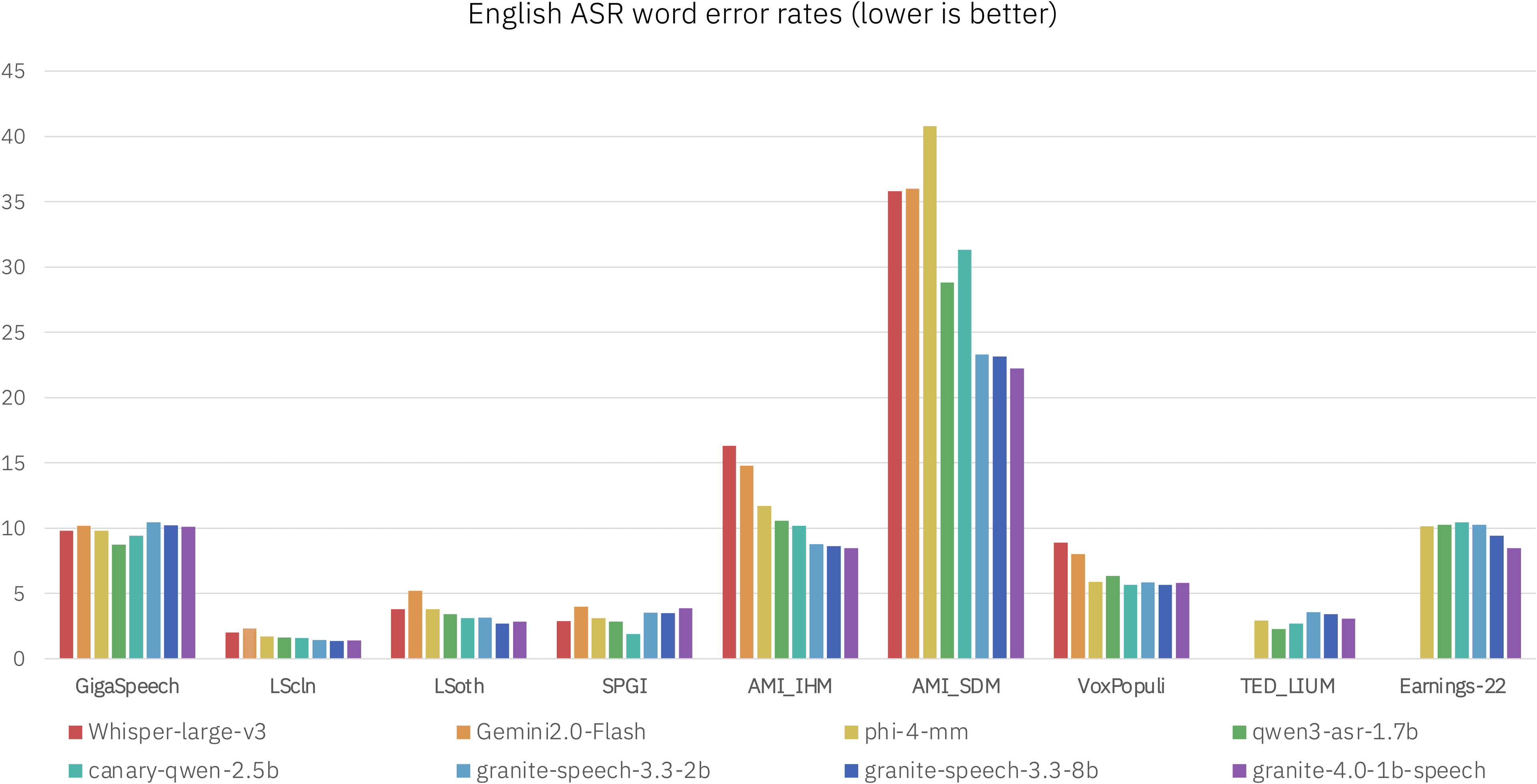
The new Apache 2.0-licensed model is part of the company's Granite family and aims to provide high-quality speech-to-text across several languages.
Resemble AI releases MIT-licensed speech-to-text models that claim higher accuracy than OpenAI's Whisper Large v3.
The new open-source tool, based on the Qwen3 architecture, precisely synchronizes audio recordings with their corresponding text transcripts.
Alibaba's Qwen team has released a new 1.7-billion-parameter model designed specifically for automatic speech recognition.
The new 600-million-parameter Qwen3-ASR model is designed for efficient, high-quality audio transcription under a permissive license.
The company, known for its powerful text models, has released its first open-source speech recognition system designed for real-time, multilingual transcription.
The new open-source automatic speech recognition model handles multilingual transcription and speaker identification out of the box.
The 8-billion-parameter model from Alibaba's Qwen team understands and generates spoken responses, enabling more natural audio-first applications.
The new speech recognition model from DeepMind is trained specifically on medical dictation, aiming for higher accuracy in clinical notes.
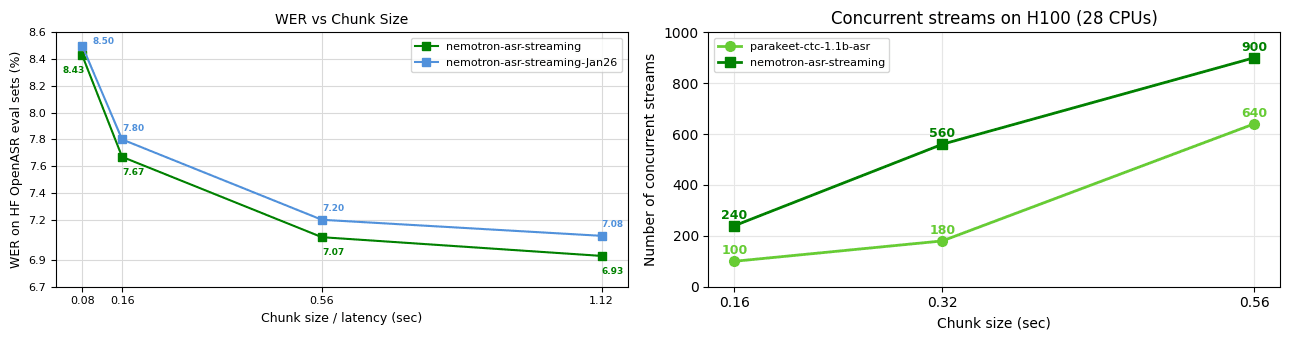
The 600-million-parameter Nemotron model is designed for real-time English transcription using a cache-aware FastConformer architecture.
The new Fun-ASR-Nano model from Alibaba's team packs real-time multilingual transcription, speaker diarization, and hotword detection into an efficient package.
The new GLM-ASR-Nano model is designed for efficient automatic speech recognition in both English and Mandarin Chinese.
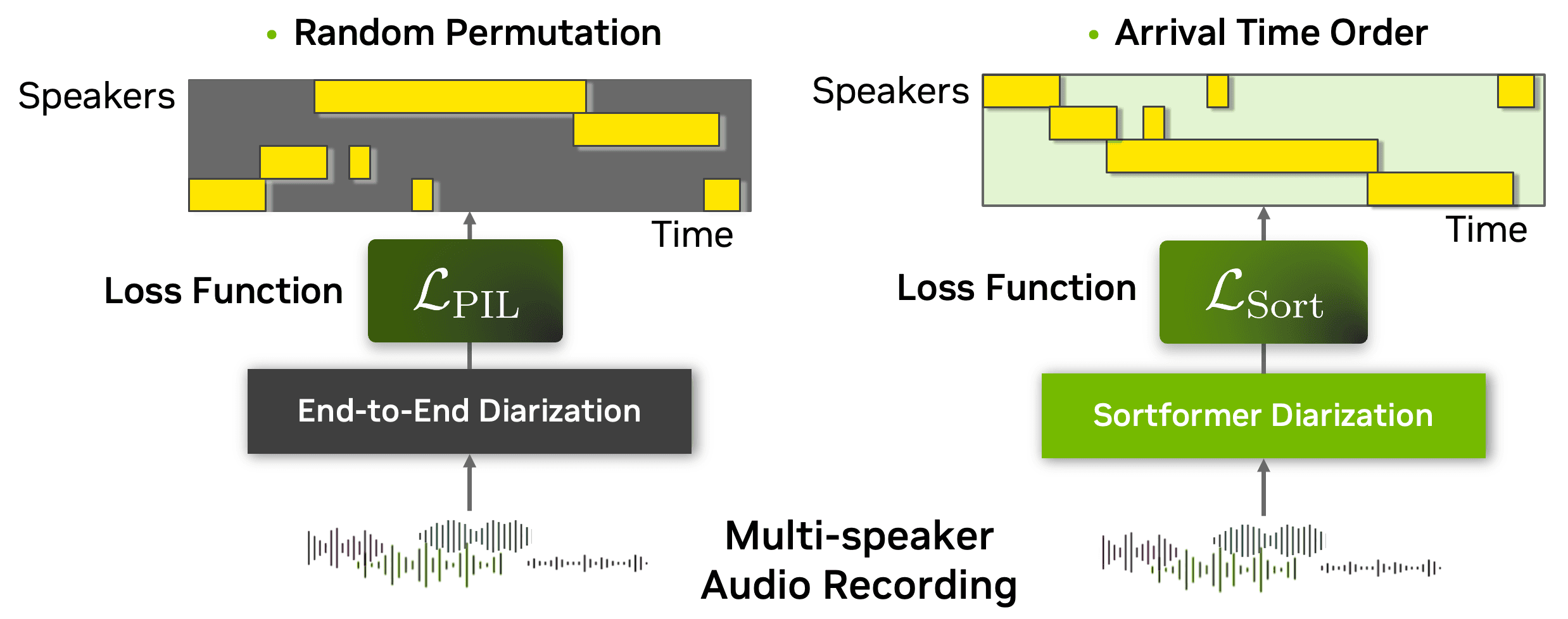
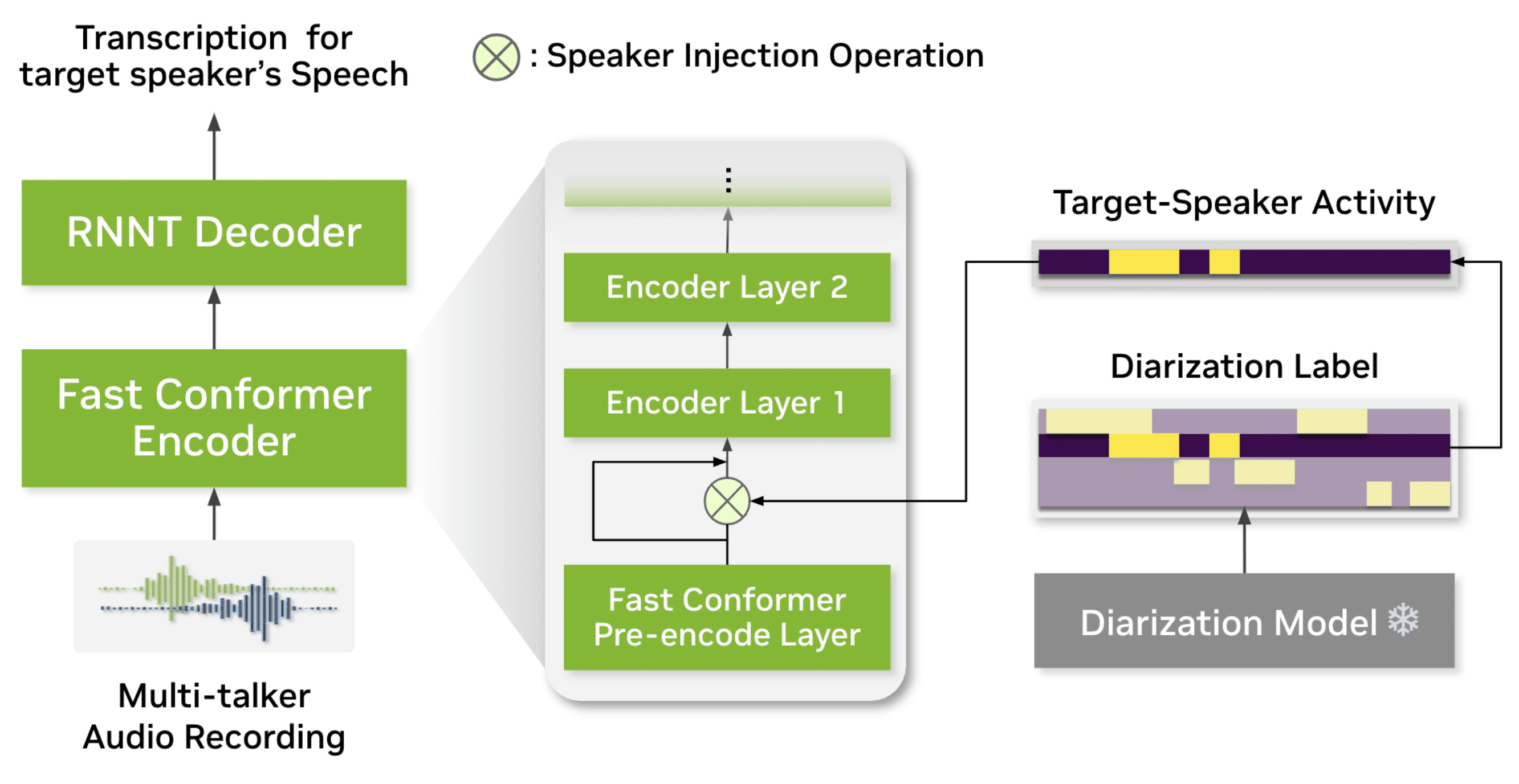
The new Sortformer-based model is designed for streaming audio, identifying up to four distinct speakers in real time.
The 600-million-parameter model offers real-time speech-to-text with speaker diarization, built on the efficient FastConformer architecture.
A new 16-billion-parameter model from inclusionAI uses a Mixture-of-Experts architecture to handle a wide range of audio tasks efficiently.
The new 30B Mixture-of-Experts model from Alibaba's Qwen team can process and generate content across text, image, and audio formats.
This new instruction-tuned model from Xiaomi can handle a flexible combination of audio and text inputs and outputs, from transcription to voice synthesis.
The new open-source model handles both speech recognition and audio generation in a single, end-to-end architecture.
The new 1-billion-parameter model handles both transcription and translation across five languages using the company's efficient FastConformer architecture.
The new FastConformer model uses a specialized training technique to improve transcription accuracy in noisy, real-world environments.
The new streaming Conformer model from the Russian digital bank is optimized for real-time transcription of telephone conversations.
The 2.5 billion-parameter speech model combines a FastConformer encoder with a Qwen LLM decoder, a hybrid approach to transcription.