NVIDIA's Parakeet ASR Tackles Multi-Speaker Audio
The 600-million-parameter model offers real-time speech-to-text with speaker diarization, built on the efficient FastConformer architecture.
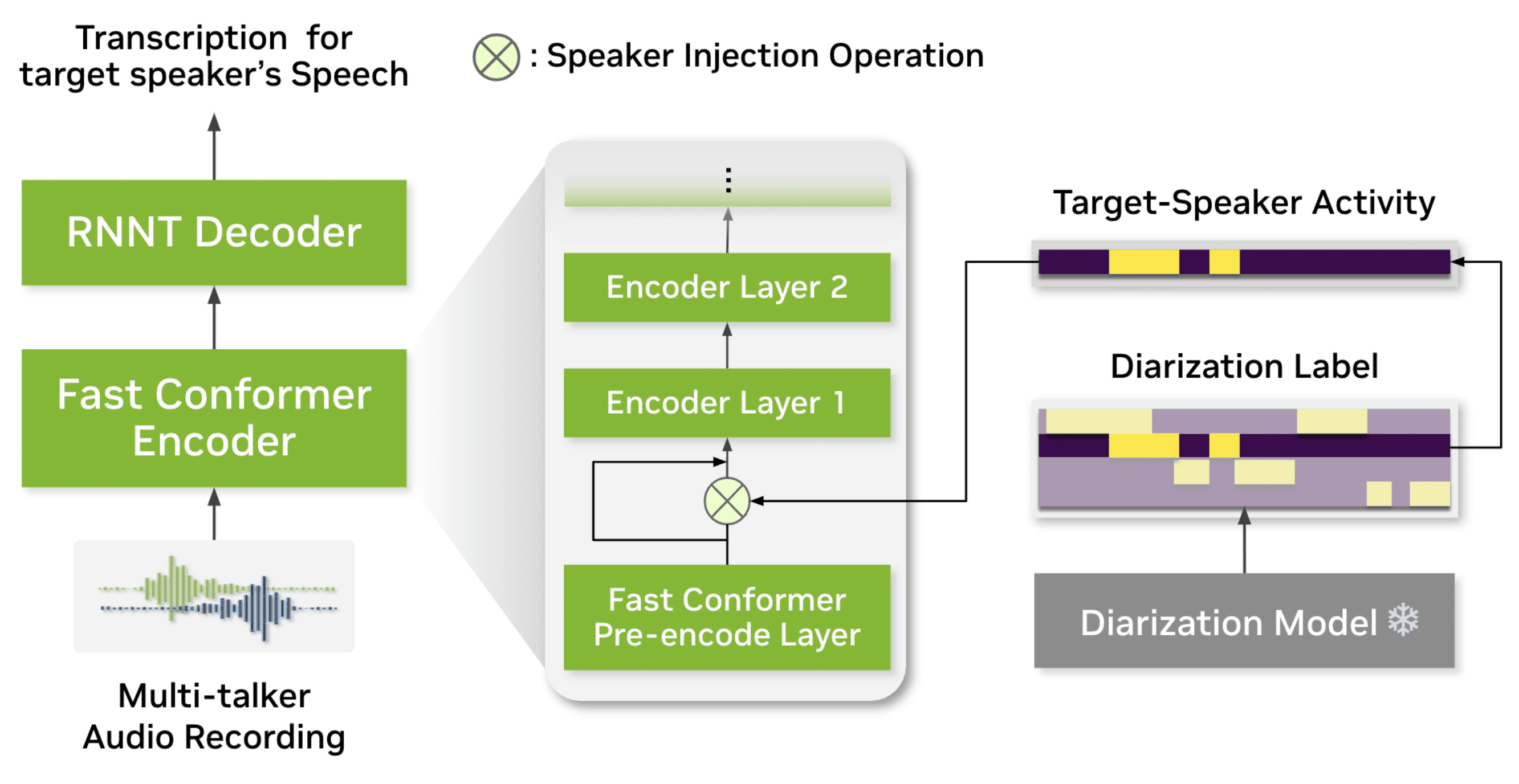
NVIDIA has released Multitalker Parakeet Streaming 0.6B, a new open model designed to transcribe conversations with multiple participants in real time. The 600-million-parameter model addresses a common challenge for automatic speech recognition (ASR) systems: accurately capturing dialogue when more than one person is speaking.
Real-Time Diarization
The model's key capability is speaker diarization—the process of determining "who spoke when." By integrating this directly into its architecture, Parakeet can attribute transcribed text to the correct speaker as the audio is being processed. This "streaming" functionality, built on the efficient FastConformer architecture, is essential for live applications where low latency is critical.
This approach is a notable step forward for creating more useful and accurate automated transcripts. Potential applications include:
- Live transcription and captioning for meetings and events.
- Analyzing multi-participant audio from call centers.
- Creating searchable records of interviews or panel discussions.
Available now on Hugging Face, the Multitalker Parakeet Streaming 0.6B model is released under the NVIDIA Open Model License Agreement. While not a traditional permissive open-source license, it allows for broad access and use of the model's weights. Its relatively compact size could enable deployment in a wide range of on-device or cloud environments.
Sources
- Visit
nvidia/multitalker-parakeet-streaming-0.6b-v1
Hugging Face
More in Speech → Text

KRAFTON releases A.X-K2 Raon speech MoE model
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.

Microsoft's VibeVoice ASR Goes BitNet for CPU Speech
A BitNet-quantized speech recognition model trades GPU dependence for efficient CPU inference in English and Chinese.

CrisperWhisper 2.0 Large targets verbatim transcription
A Whisper-based ASR model that keeps every filler word and stamps timestamps to the individual word, now covering English and German.
0 comments
No comments yet. Be the first to weigh in.