NVIDIA/Any-to-Any
NVIDIA's Audio-Visual Flamingo Fuses Sound and Sight
A fully open multimodal model aims to reason jointly across audio, images, and long-form video.

Company
Releases
A fully open multimodal model aims to reason jointly across audio, images, and long-form video.
The 8-billion-parameter text embedding model claims the number one overall spot on the RTEB benchmark, with an eye toward agentic retrieval.
A compact 1B-parameter text embedding model claims the top overall spot on a retrieval benchmark aimed at reflecting real-world use.
A new 30B mixture-of-experts model from NVIDIA handles both listening and speaking within a single audio-text architecture.
A new edge-optimized variant of NVIDIA's Cosmos world-model line aims to run generative video where the compute lives.
A DMD2-distilled build of Qwen-Image trades sampling steps for speed while keeping the original model's output profile.
A 230-million-parameter language model built to run on hardware as modest as a Raspberry Pi.
A 75-billion-parameter mixture-of-experts reasoning model that activates just 9 billion parameters per token.
The 75B-parameter model activates just 9B per token and ships in NVIDIA's NVFP4 format for efficient inference.
The latest release in NVIDIA's 'world model' research family aims to generate coherent and realistic video from a single static image.
The new model, SANA-WM, uses a bidirectional diffusion process to give creators fine-grained control over camera movement and video editing.
The 600-million-parameter model uses a FastConformer architecture for real-time, multilingual speech-to-text applications.
The new component is a specialized VAE decoder that works with Stability AI's Z-Image model to enhance super-resolution tasks.
The new 30-billion parameter Mixture-of-Experts model handles text and images while using only 3 billion active parameters for inference.
The new 30-billion-parameter Mixture-of-Experts model handles any combination of modalities with just 3 billion active parameters.
An experimental 30B mixture-of-experts base model blends diffusion and Mamba ideas under a two-tower design.
A new 30B mixture-of-experts base model activates just 3B parameters per token and pairs a hybrid diffusion/Mamba design.
The new 3-billion-parameter model, based on the company's Eagle architecture, is designed for high-precision visual grounding tasks.
The 600-million-parameter Nemotron model is designed for real-time English transcription using a cache-aware FastConformer architecture.
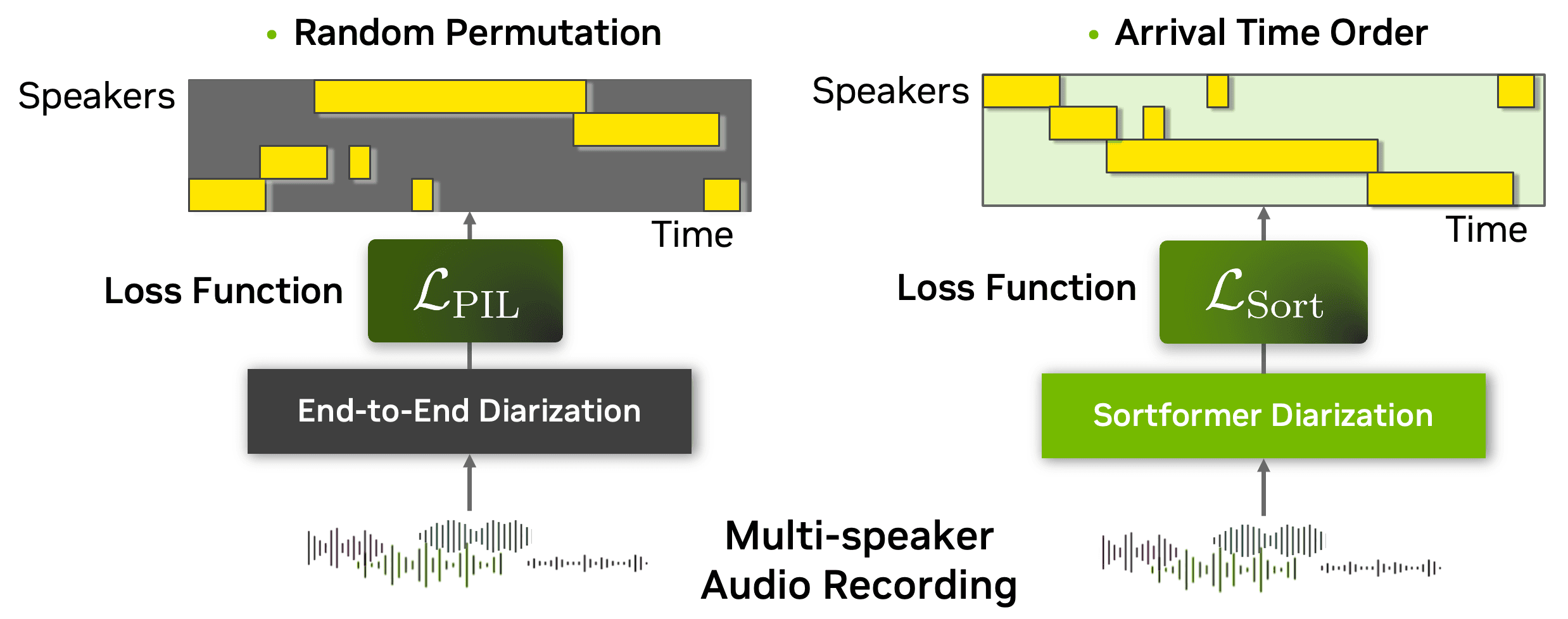
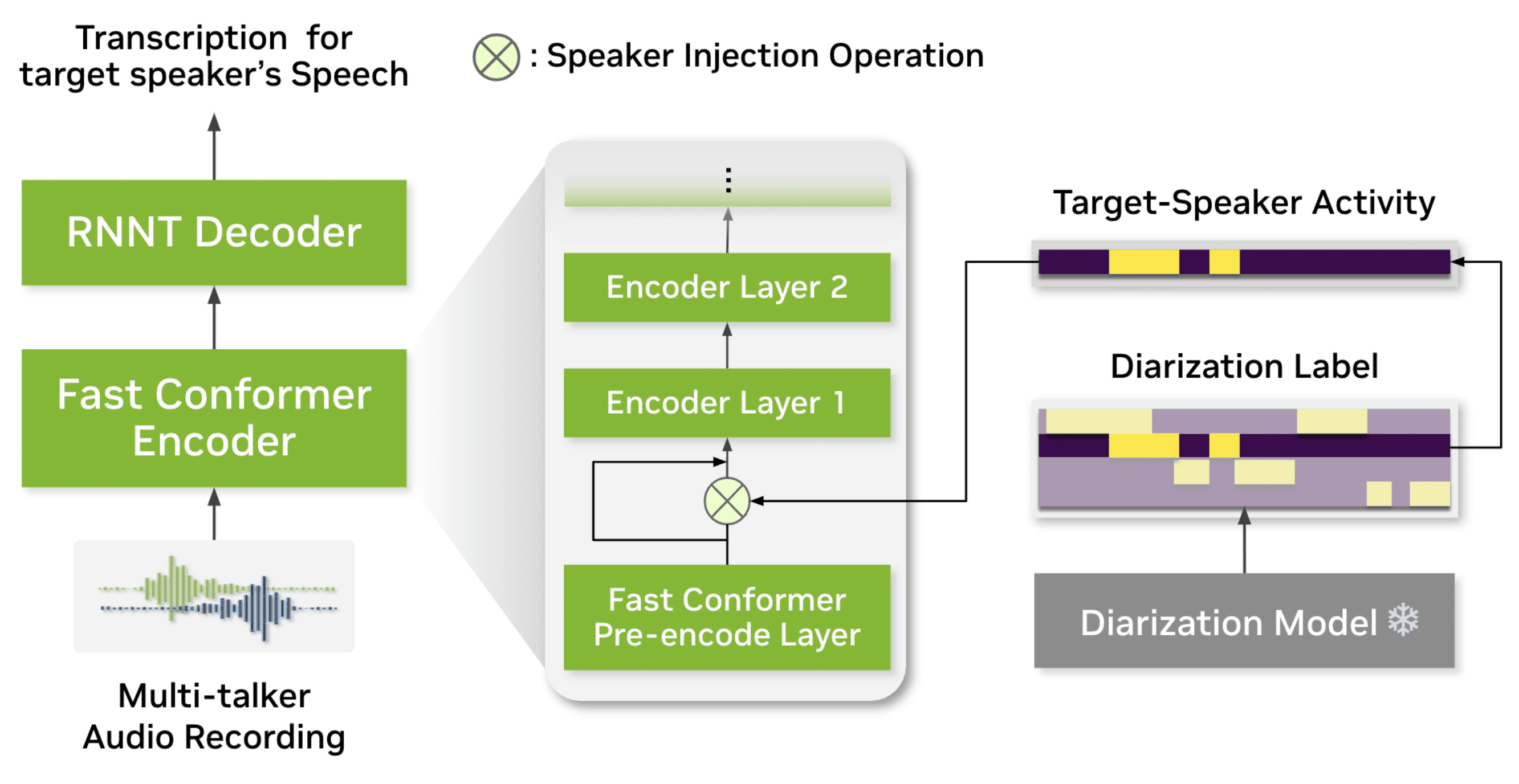
The new Sortformer-based model is designed for streaming audio, identifying up to four distinct speakers in real time.
The 600-million-parameter model offers real-time speech-to-text with speaker diarization, built on the efficient FastConformer architecture.
The new 1-billion-parameter model handles both transcription and translation across five languages using the company's efficient FastConformer architecture.
The new FastConformer model uses a specialized training technique to improve transcription accuracy in noisy, real-world environments.
The 2.5 billion-parameter speech model combines a FastConformer encoder with a Qwen LLM decoder, a hybrid approach to transcription.