NVIDIA Releases Streaming Speech-to-Text Model
The 600-million-parameter Nemotron model is designed for real-time English transcription using a cache-aware FastConformer architecture.
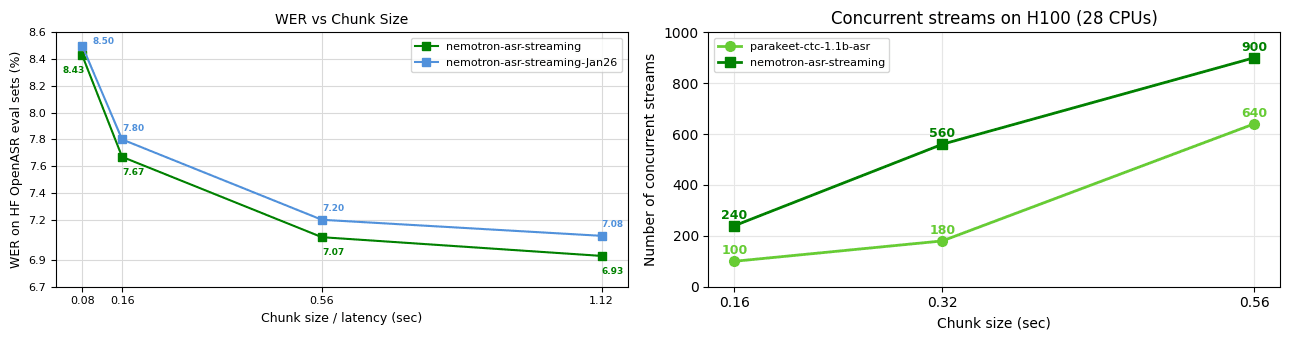
NVIDIA has released a new model for automatic speech recognition (ASR), Nemotron Speech Streaming EN 0.6B. This 600-million-parameter model is specifically engineered for real-time, streaming transcription of English audio, making it suitable for applications that require immediate output.
Built for Real-Time Performance
The model is based on the FastConformer architecture, an effective design for speech recognition. Its key feature is its "cache-aware streaming" capability, which allows it to process audio in small chunks as it arrives rather than waiting for an entire recording. By intelligently managing its internal state, or cache, between these chunks, the model can deliver continuous transcription with minimal delay.
This streaming approach is critical for interactive voice applications. Potential use cases include:
- Live captioning for broadcasts and events
- Responsive voice assistants
- Real-time transcription for meetings or customer service calls
By releasing a specialized model for this task, NVIDIA provides developers with another tool for building responsive, voice-enabled products. The model is available on Hugging Face under the NVIDIA Open Model License Agreement, and interested users can find full details in the official repository.
Sources
- Visit
nvidia/nemotron-speech-streaming-en-0.6b
Hugging Face
More in Speech → Text

KRAFTON releases A.X-K2 Raon speech MoE model
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.

Microsoft's VibeVoice ASR Goes BitNet for CPU Speech
A BitNet-quantized speech recognition model trades GPU dependence for efficient CPU inference in English and Chinese.

CrisperWhisper 2.0 Large targets verbatim transcription
A Whisper-based ASR model that keeps every filler word and stamps timestamps to the individual word, now covering English and German.
0 comments
No comments yet. Be the first to weigh in.