NVIDIA Releases Real-Time Speaker Diarization Model
The new Sortformer-based model is designed for streaming audio, identifying up to four distinct speakers in real time.
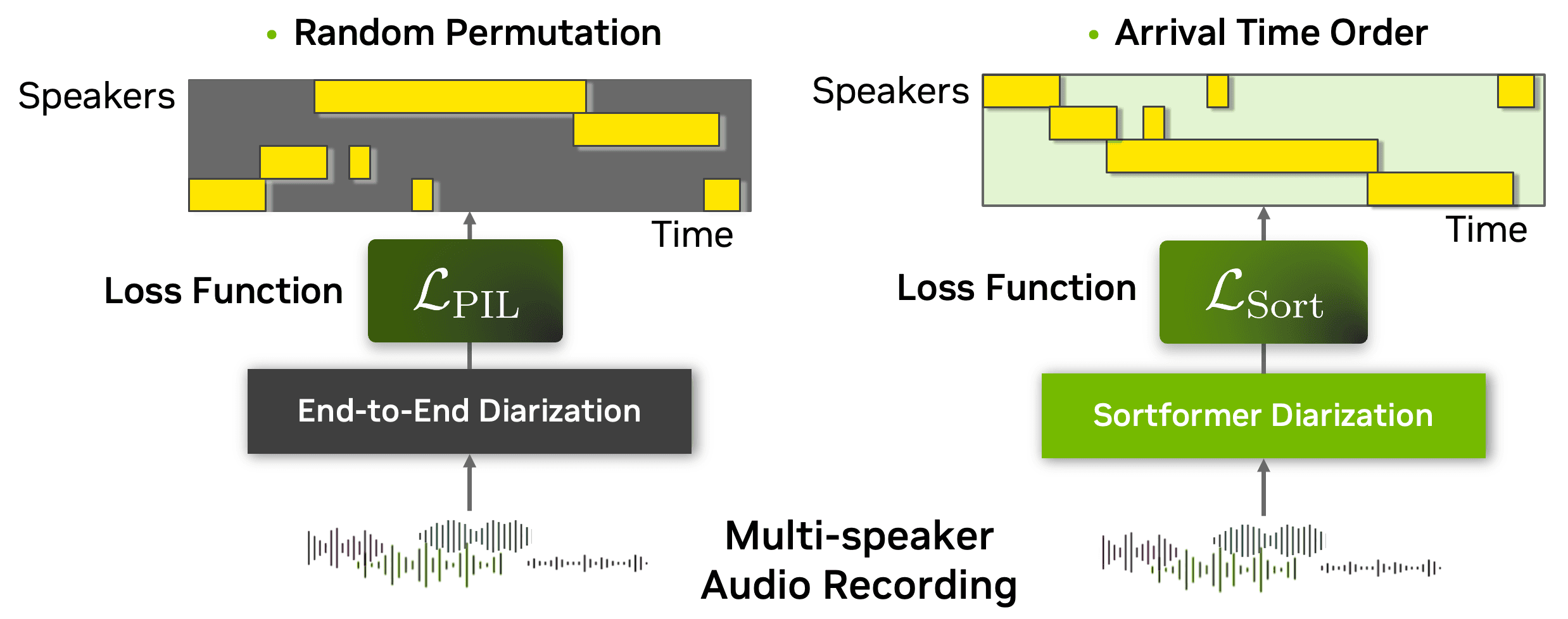
NVIDIA has released a new model aimed at a core challenge in audio processing: figuring out "who spoke when" in real time. The new system, Streaming Sortformer Diarization 4spk v2.1, is designed for speaker diarization on continuous audio streams, a key component for building sophisticated conversational AI.
Unlike traditional diarization systems that process an entire audio file after it has been recorded, this model's "streaming" capability allows it to work on live audio. This is essential for applications like real-time meeting transcription, automated call center analysis, and live captioning, where identifying the current speaker without delay is critical.
Technical Details
The model uses a Transformer-based architecture called Sortformer and is optimized for common conversational scenarios. Its key features include:
- Speaker Capacity: Supports up to four distinct speakers.
- Real-time Processing: Designed for low-latency, continuous input.
- Toolkit Integration: Intended for use with the NVIDIA NeMo toolkit for conversational AI.
The model is available for download on the Hugging Face Hub. It is released under a custom NVIDIA AI Foundation Models EULA, not a traditional open-source license, which may limit its use in some commercial applications.
Sources
- Visit
nvidia/diar_streaming_sortformer_4spk-v2.1
Hugging Face
More in Speech → Text

KRAFTON releases A.X-K2 Raon speech MoE model
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.

Microsoft's VibeVoice ASR Goes BitNet for CPU Speech
A BitNet-quantized speech recognition model trades GPU dependence for efficient CPU inference in English and Chinese.

CrisperWhisper 2.0 Large targets verbatim transcription
A Whisper-based ASR model that keeps every filler word and stamps timestamps to the individual word, now covering English and German.
0 comments
No comments yet. Be the first to weigh in.