IBM Releases 1B Granite Model for Multilingual Speech
The new Apache 2.0-licensed model is part of the company's Granite family and aims to provide high-quality speech-to-text across several languages.
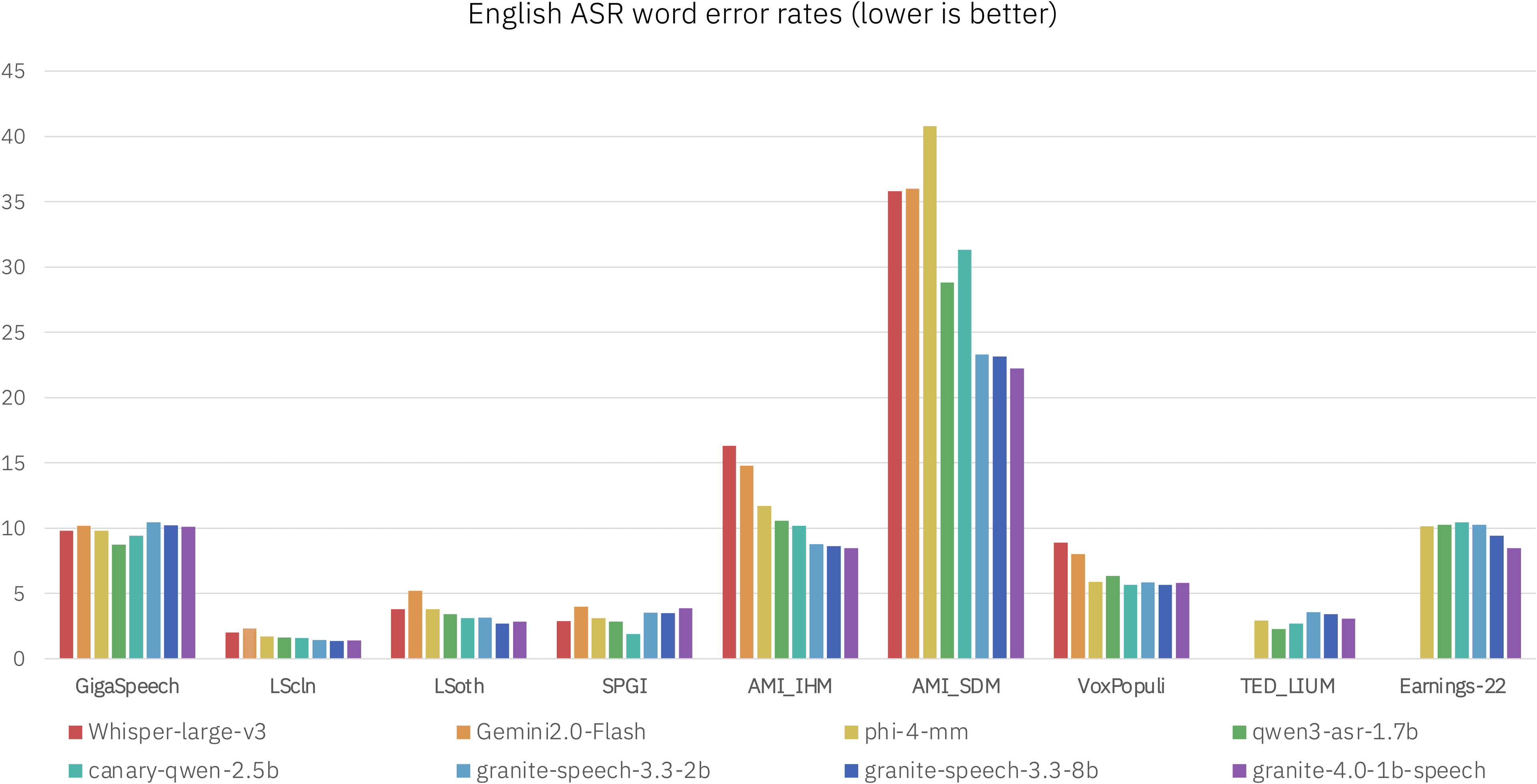
IBM has expanded its open-source Granite model family with the release of a new 1-billion-parameter model specialized for automatic speech recognition (ASR). The new release, named Granite 4.0 1B Speech, is designed for multilingual speech-to-text tasks and is available under the permissive Apache 2.0 license, allowing for commercial use.
This model employs a Conformer-based encoder-decoder architecture, a proven approach for capturing both local and global features in audio sequences. According to IBM's documentation, it was trained on a combination of proprietary and public datasets to achieve robust performance across different languages and acoustic environments.
A New Contender in Open ASR
The release of a high-quality, commercially-viable speech model from a major enterprise player like IBM provides a significant new option for developers. It enters a field largely defined by models like OpenAI's Whisper, offering another powerful, open foundation for building applications such as transcription services, voice-enabled interfaces, and accessibility tools.
At one billion parameters, Granite Speech strikes a balance between performance and computational efficiency, making it a more accessible choice for deployment compared to larger, more resource-intensive models. Developers and researchers can access the model and its usage documentation on the Hugging Face Hub.
Sources
- Visit
ibm-granite/granite-4.0-1b-speech
Hugging Face
More in Speech → Text

KRAFTON releases A.X-K2 Raon speech MoE model
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.

Microsoft's VibeVoice ASR Goes BitNet for CPU Speech
A BitNet-quantized speech recognition model trades GPU dependence for efficient CPU inference in English and Chinese.

CrisperWhisper 2.0 Large targets verbatim transcription
A Whisper-based ASR model that keeps every filler word and stamps timestamps to the individual word, now covering English and German.
0 comments
No comments yet. Be the first to weigh in.