OpenMOSS Releases MOVA for Joint Video and Audio Gen
The new model generates 360p video from text or images and creates corresponding audio tracks simultaneously, a notable step for integrated audiovisual synthesis.
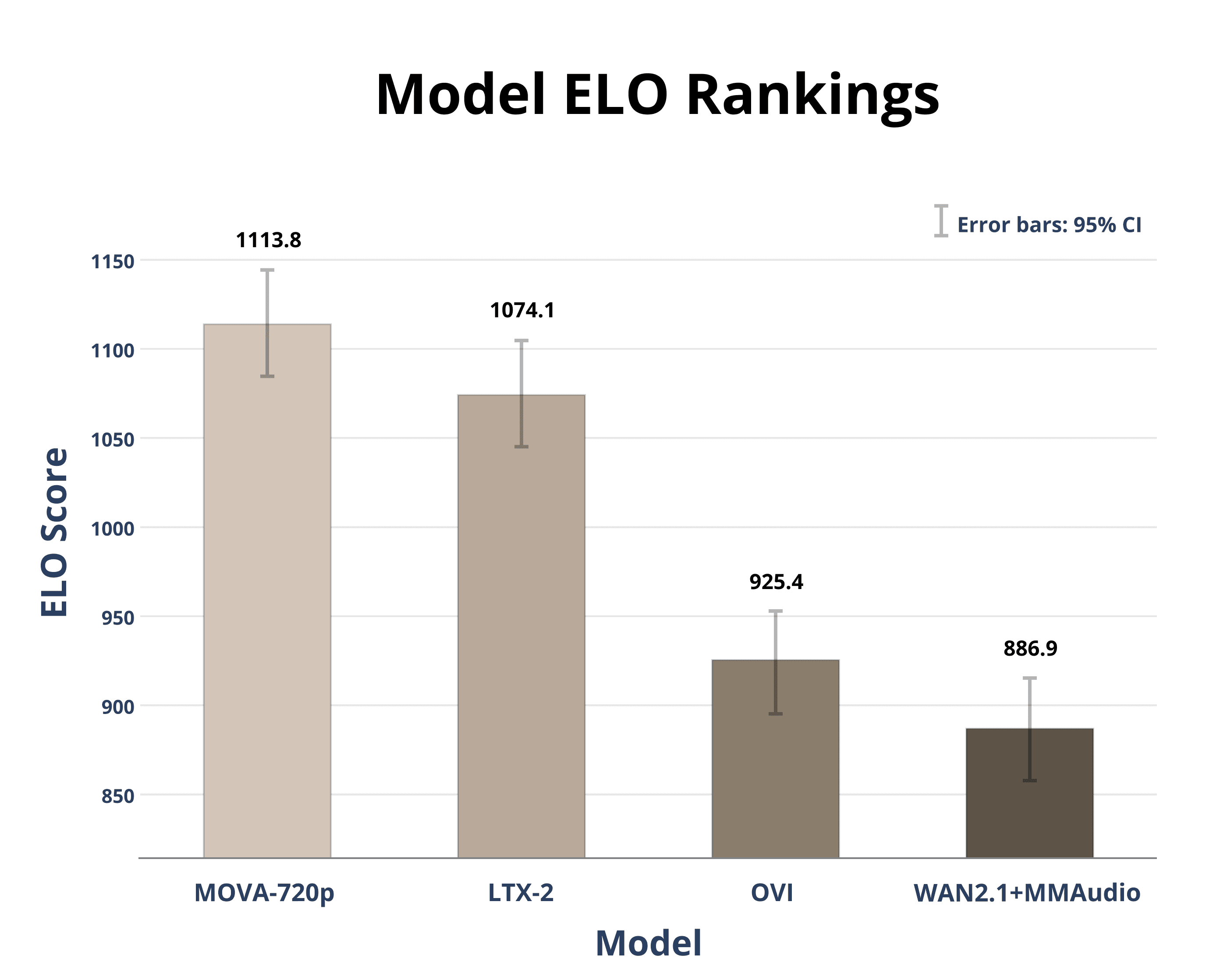
The OpenMOSS team has introduced MOVA-360p, a new generative model that can create short video clips from either a text description or a starting image. While many recent models focus on visual generation, MOVA stands out by tackling both video and audio in a single process.
MOVA's key feature is its ability to perform joint audio-video generation. Instead of producing a silent video that requires a separate soundtrack, the model synthesizes an accompanying audio track that is thematically consistent with the visual content. This integrated approach aims to create more immersive and complete generative media.
The model architecture is built upon established open-source components, using a Stable Diffusion 1.5 foundation for the visual elements and an audio generation model named Tango for the sound. It outputs clips at a resolution of 360p, positioning it as a tool for research and experimentation in multimodal generation.
Researchers and developers can explore the model, which is available on Hugging Face. The release is provided under a custom license, so users should review the terms to ensure compliance for their specific use cases. You can find the model card and download the weights at the official repository.
Sources
- Visit
OpenMOSS-Team/MOVA-360p
Hugging Face
More in Image → Video

MiniMax Releases H3 Video Model on Hugging Face
The company's new diffusion model handles text-to-video and image-to-video, with support for joint audio-video generation.

Wan-Dancer-14B turns still images into dance videos
Alibaba's Wan team releases an Apache-2.0 image-to-video model built for music-driven dance generation.

NVIDIA's Cosmos 3 Edge Brings World Models Closer
A new edge-optimized variant of NVIDIA's Cosmos world-model line aims to run generative video where the compute lives.
0 comments
No comments yet. Be the first to weigh in.