ByteDance Releases Lance, a Unified Generative AI Model
The 3-billion-parameter model handles image and video generation, editing, and understanding from a single set of weights under a permissive license.
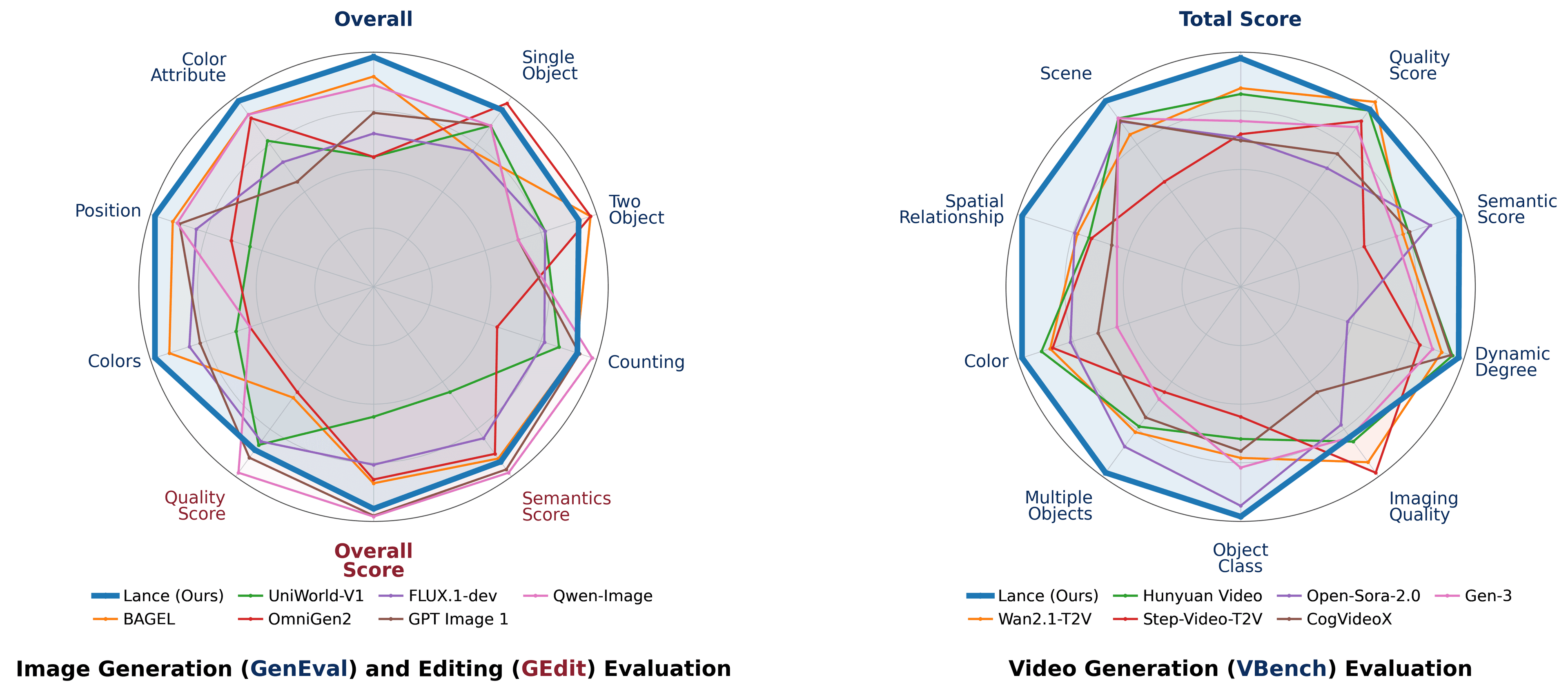
ByteDance has released Lance, a new 3-billion-parameter generative model that takes a unified approach to multimodal tasks. Released under a permissive Apache 2.0 license, Lance is designed to handle a wide range of creative and analytical tasks involving both images and video using a single, cohesive architecture.
The model's key innovation is its unified nature. Instead of relying on separate, specialized models for different tasks—one for generating images, another for editing video—Lance integrates these capabilities into one system. This design allows it to perform generation, editing, and understanding across different media formats without switching contexts or toolchains.
A Multi-Talented Architecture
Lance's single framework is trained to handle several distinct creative functions. According to the release documentation, its primary skills include:
- Text-to-Image and Text-to-Video Generation: Creating visual content from text prompts.
- Image Editing: Modifying existing images based on instructions.
- Multimodal Understanding: Analyzing and interpreting the content of images and video.
This release provides the open-source community with a powerful and flexible tool for building complex creative applications. By consolidating multiple functions into a relatively compact model, Lance offers an efficient alternative to more fragmented, multi-model pipelines. Researchers and developers can explore the model's weights and architecture, which are available on its Hugging Face repository.
Sources
- Visit
bytedance-research/Lance
Hugging Face
More in Any-to-Any

Thinking Machines Debuts Inkling Small, a Compact Multimodal MoE
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.

KRAFTON releases A.X-K2 Raon speech MoE model
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.

Microsoft's Mage-VL Streams Video Natively
A codec-native multimodal foundation model aims to understand live video and vision-language input in real time.
0 comments
No comments yet. Be the first to weigh in.