Baidu Releases Open VLM for Advanced Document OCR
The new PaddleOCR-VL model is built to parse not just text, but also the tables, formulas, and page layouts found in complex documents.
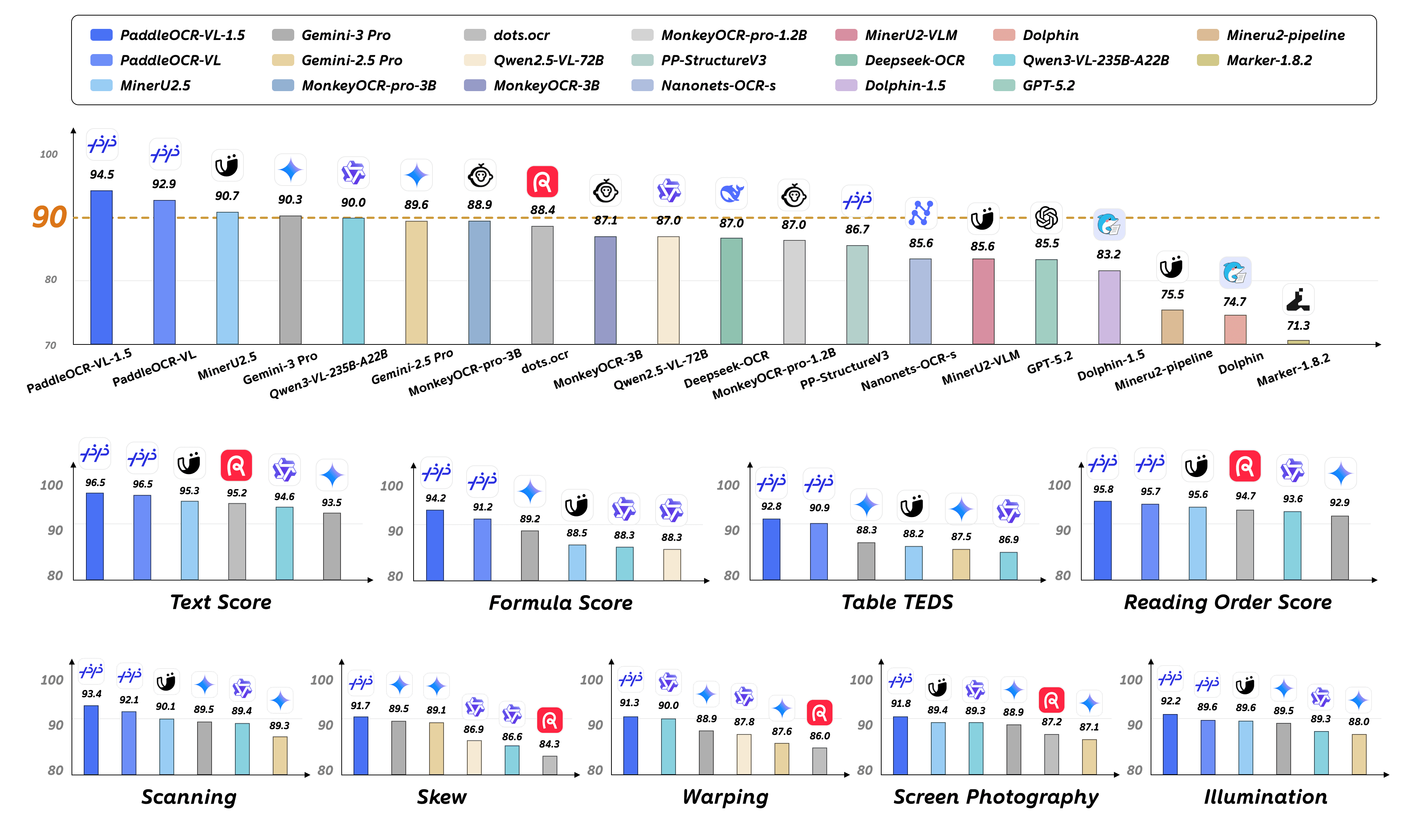
Baidu has released PaddleOCR-VL-1.5, a new open-source vision-language model specialized in advanced document analysis. Released under a permissive Apache 2.0 license, the model aims to move beyond simple text extraction to understand the full structure and content of complex documents.
Unlike traditional OCR tools that focus solely on converting characters, PaddleOCR-VL is designed to handle a wider range of document intelligence tasks. According to its release notes, its key capabilities include:
- Full-page layout parsing
- Table structure recognition and extraction
- Mathematical formula detection
- Chart and graph analysis
This makes the model particularly suited for applications in academic research, finance, and enterprise document management, where information is often presented in structured, non-prose formats.
The model is based on Baidu's ERNIE 4.5 foundation, extending its multimodal capabilities specifically for the document OCR domain. By open-sourcing this specialized tool, Baidu provides developers with a powerful component for building applications that can digitize and interpret intricate information from images and scans. The model is available now on Hugging Face for community use and development.
Sources
- Visit
PaddlePaddle/PaddleOCR-VL-1.5
Hugging Face
More in Vision-Language

Thinking Machines Debuts Inkling Small, a Compact Multimodal MoE
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.

Microsoft's Mage-VL Streams Video Natively
A codec-native multimodal foundation model aims to understand live video and vision-language input in real time.

Apertus v1.5 70B arrives with an Apache-2.0 license
Switzerland's open-model effort ships a 70-billion-parameter, multilingual and multimodal system that anyone can use, modify, and deploy.
0 comments
No comments yet. Be the first to weigh in.