SenseTime Releases 8B 'Any-to-Any' Infographic Model
The new 8B-parameter SenseNova U1 model from SenseTime is designed for complex multimodal tasks, including the in-conversation generation and editing of infographics.
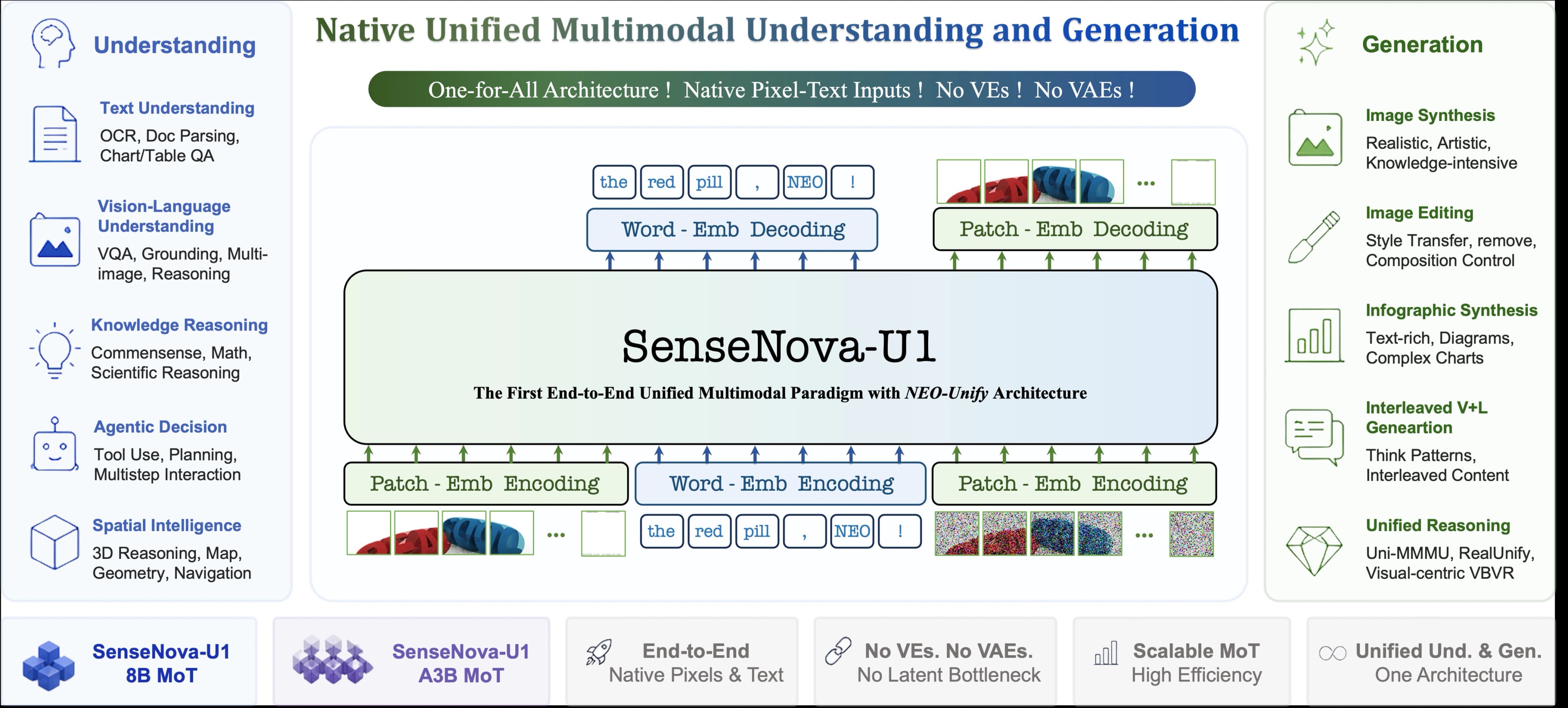
SenseTime has released SenseNova U1 8B MoT Infographic, an 8-billion-parameter model with a unique focus on creating and editing complex visual documents. The model represents a step forward in conversational AI, moving beyond simple prompts to handle 'any-to-any' interactions with interleaved text and images.
What sets SenseNova U1 apart is its 'Mixture of Talents' (MoT) architecture, which combines a large language model with a diffusion model. This allows it to not only generate images from text but also to understand and execute follow-up commands to edit those images within the same conversation. This is particularly useful for iterative design tasks, like building an infographic piece by piece.
According to the model card on Hugging Face, the system is designed to seamlessly switch between understanding user intent, generating visual elements, and continuing a natural-language dialogue.
Key Capabilities
- Any-to-Any Interaction: Can process and generate mixed sequences of text and images.
- In-Context Generation: Creates new images mid-conversation based on the preceding dialogue.
- Infographic Focus: Specialized skills for generating and editing charts, diagrams, and other infographic elements.
The model's weights are available for research and non-commercial use. While not a fully open-source release for commercial applications, it provides researchers with a powerful tool for exploring the frontier of generative multimodal AI.
Sources
- Visit
sensenova/SenseNova-U1-8B-MoT-Infographic
Hugging Face
More in Any-to-Any

Thinking Machines Debuts Inkling Small, a Compact Multimodal MoE
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.

KRAFTON releases A.X-K2 Raon speech MoE model
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.

Microsoft's Mage-VL Streams Video Natively
A codec-native multimodal foundation model aims to understand live video and vision-language input in real time.
0 comments
No comments yet. Be the first to weigh in.