Meituan Debuts LongCat-Flash-Omni, an Any-to-Any AI Model
The new open-source Mixture-of-Experts model can process and generate any combination of text, images, video, audio, and 3D data.
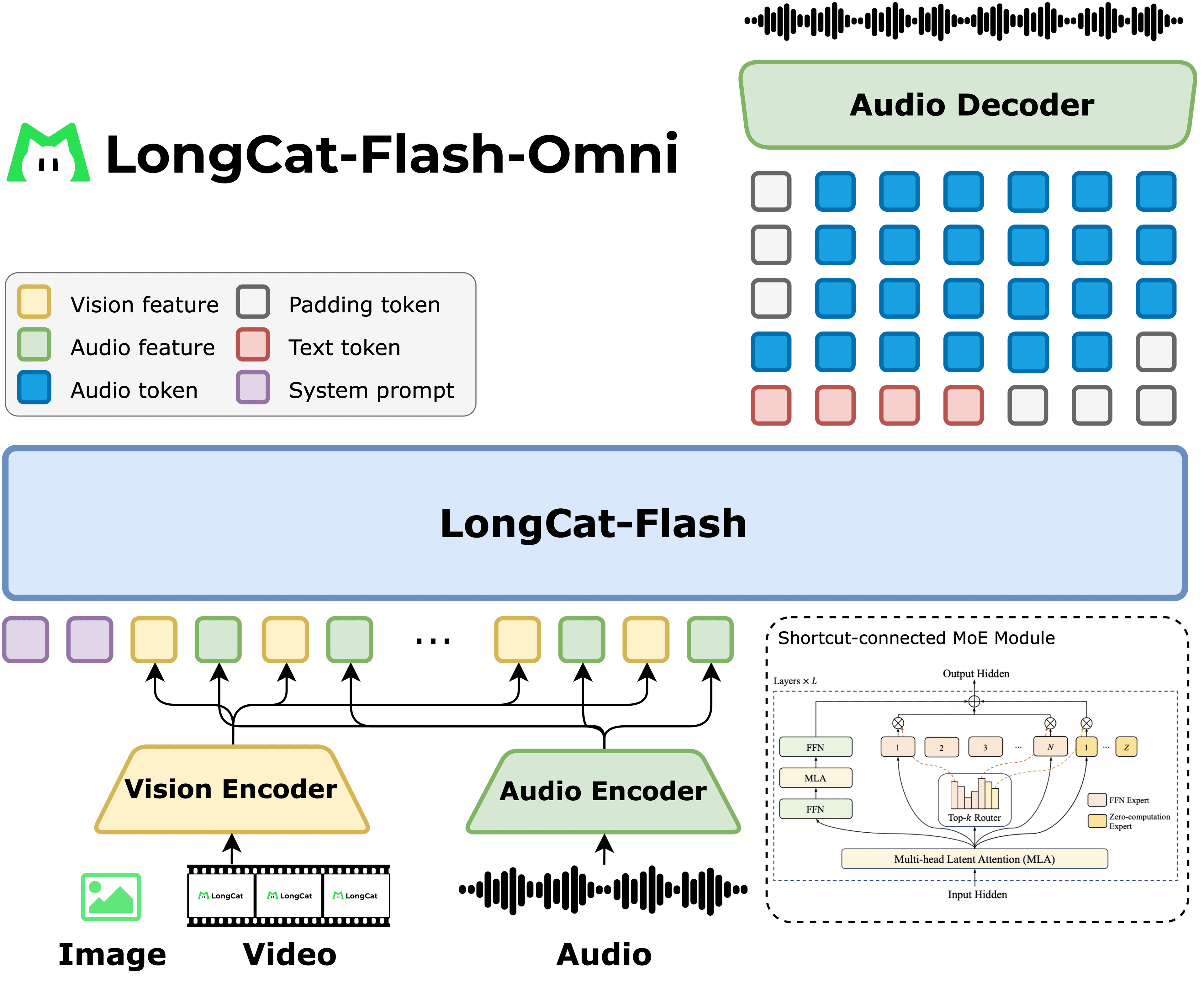
Chinese technology company Meituan has released LongCat-Flash-Omni, a new open-source model designed to handle a vast array of data types. Billed as an "any-to-any" omni-modal system, it aims to process and generate information across different formats seamlessly, a significant step in developing more versatile AI.
According to the release details on Hugging Face, the model's key innovation is its ability to manage multiple data modalities simultaneously within a single framework. This "omni-modal" capability includes:
- Text
- Images
- Video
- Audio
- 3D data
The model is built on a Mixture-of-Experts (MoE) architecture, a technique that activates specialized parts of the network for specific tasks. This allows the model to scale efficiently while managing the complexity of different data encoders. The system projects inputs from various modalities into a shared representational space, allowing the core language model to process them cohesively.
Released under the permissive MIT license, LongCat-Flash-Omni provides the research community with a powerful tool for exploring truly multimodal AI. Its flexible architecture opens up possibilities for complex applications that require understanding and generating content across diverse formats, pushing the boundaries of what's possible with open-source models.
Sources
- Visit
meituan-longcat/LongCat-Flash-Omni
Hugging Face
More in Any-to-Any

Thinking Machines Debuts Inkling Small, a Compact Multimodal MoE
The Apache-2.0 model brings mixture-of-experts efficiency to image, audio, and text tasks in a smaller footprint.

KRAFTON releases A.X-K2 Raon speech MoE model
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.

Microsoft's Mage-VL Streams Video Natively
A codec-native multimodal foundation model aims to understand live video and vision-language input in real time.
0 comments
No comments yet. Be the first to weigh in.