Boson AI Releases Higgs Audio v2 for Expressive TTS
The new 3-billion-parameter model focuses on generating expressive, multilingual speech and is fully open for commercial use under an Apache 2.0 license.
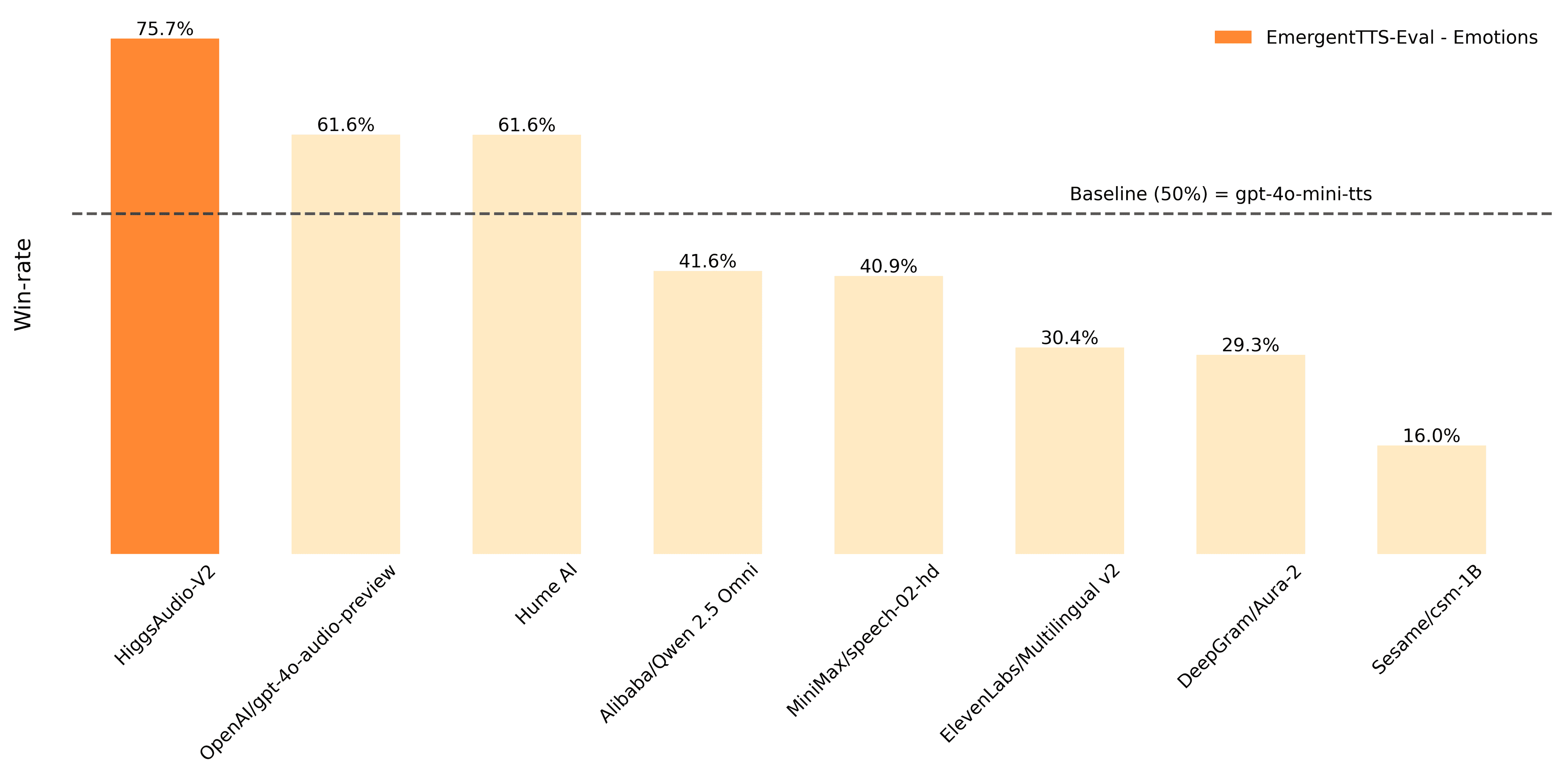
Boson AI has introduced Higgs Audio v2, a new open-source model for text-to-speech and audio generation. With three billion parameters, the model is designed to produce expressive and natural-sounding voices across multiple languages, adding a notable new entry to the competitive audio synthesis landscape.
The release is significant not just for its scale but also for its accessibility. Higgs Audio v2 is available under a permissive Apache 2.0 license, clearing the way for both research and commercial applications. This makes it a compelling alternative to proprietary APIs, offering developers a powerful foundation for building custom audio-centric features.
A Focus on Expressive Synthesis
According to Boson AI, the model specializes in "expressive voice synthesis," aiming for a higher degree of nuance and emotion in its output compared to more monotonic TTS systems. This capability is crucial for applications requiring more natural human-like speech, such as:
- Dynamic character voices in gaming and entertainment
- Engaging narration for audiobooks and podcasts
- More sophisticated and personable virtual assistants
The Higgs Audio v2 base model is now available on Hugging Face, allowing the community to begin experimenting with its capabilities and fine-tuning it for specific use cases.
Sources
- Visit
bosonai/higgs-audio-v2-generation-3B-base
Hugging Face
More in Text → Speech

Audio8 debuts a 0.6B multilingual zero-shot TTS preview
The compact text-to-speech model promises voice cloning across languages from a footprint small enough to run without heavy hardware.

KRAFTON releases A.X-K2 Raon speech MoE model
The game maker's new open model blends text-to-speech and speech recognition in a single 21B mixture-of-experts system with just 3B active parameters.

NVIDIA's Audex Unifies Audio Understanding and Speech
A new 30B mixture-of-experts model from NVIDIA handles both listening and speaking within a single audio-text architecture.
0 comments
No comments yet. Be the first to weigh in.