OpenBMB/Text / LLM
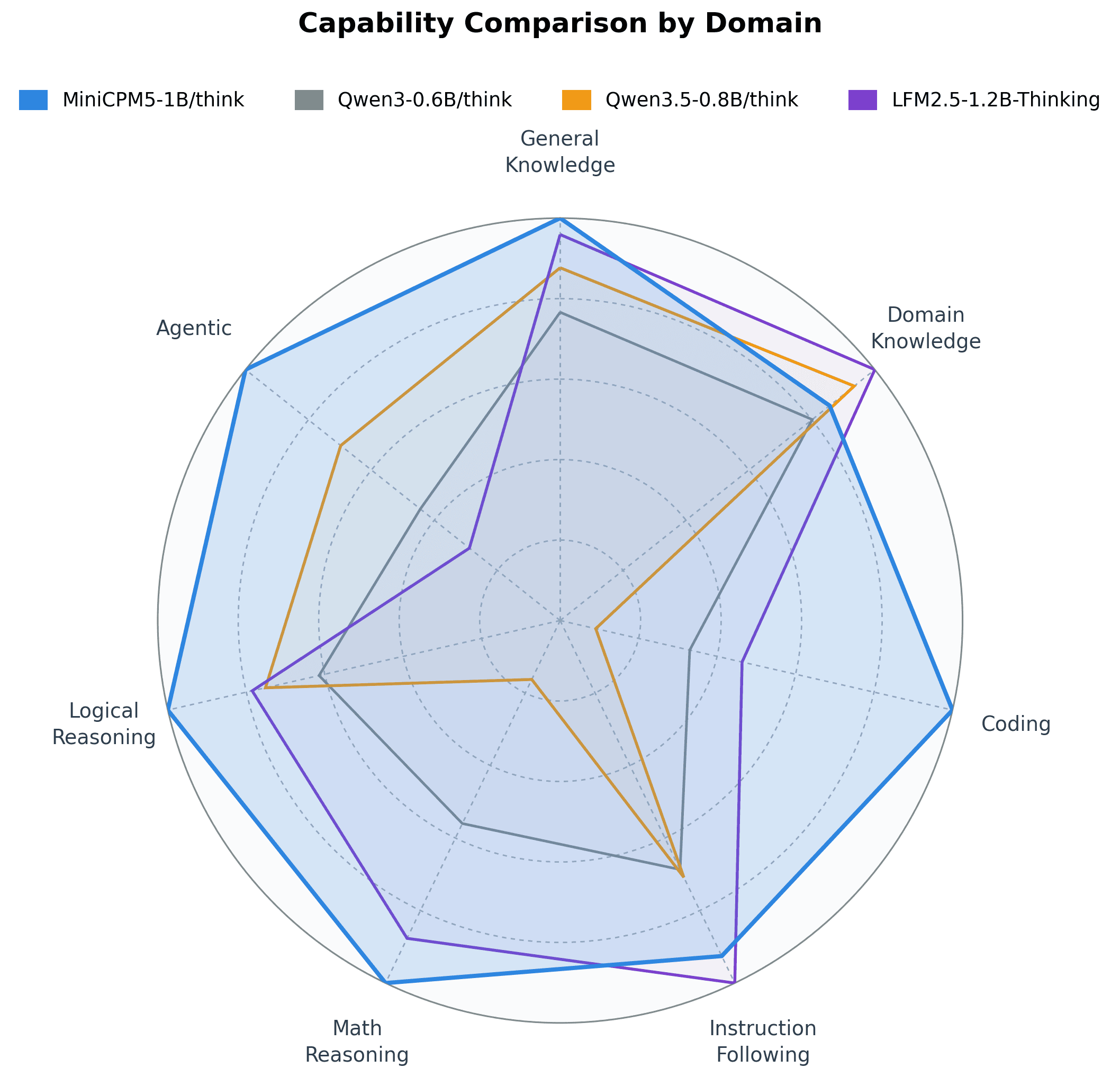
OpenBMB's MiniCPM5-1B targets on-device AI
The compact 1B-parameter model brings long-context handling and tool-calling to phones and laptops.
Company
Releases
The compact 1B-parameter model brings long-context handling and tool-calling to phones and laptops.
The team behind GLiNER releases an open-source small language model aimed at making safety moderation cheaper and quicker to run.
Cactus Compute distilled Gemini's tool-calling behavior into a tiny model meant to run locally.
The new open-source vision-language model is designed for high-resolution image understanding on mobile and edge devices.
The new diffusion-based model from the OpenBMB research group supports multilingual speech, emotional control, and zero-shot voice cloning.
The new MiniCPM-o 4.5 model from the open-source research group can process and generate interleaved combinations of images, text, and audio.
The new model from OpenBMB supports mixed-modality inputs and outputs, from text and images to audio and video, in a single efficient package.
The new 500-million-parameter text-to-speech model from OpenBMB supports both English and Chinese and can replicate a voice from a short audio sample.
The new 500-million-parameter model offers high-quality text-to-speech and zero-shot voice cloning under a permissive license.
The new vision-language model from the open-source research group demonstrates strong OCR and video understanding capabilities in a small package.